Morphing이란?
- Metamorphosis(변형)에서 유래된 말로 한 영상에서 다른 영상 사이를 연속적으로 변형시키는 형상변형이다. 즉, 서로 다른 2개의 이미지나 3차원 모델 사이의 변화하는 과정을 연속적으로 서서히 나타내는 effect를 Morphing이라고 한다. 즉, 이렇게 첫 영상과 마지막 영상 ( 프레임 )을 지정해주면 컴퓨터가 animation혹은 motion pictures와 같은 Morphing이란 special effect를 만들어낸다.
- 앞으로 살펴볼 3DMM에서 Morphing이란 결국 형상 변형이 일어나는 것이라고 생각하면 되겠다.
3DMM : 3d Morphable (Face) Model
- 일반적으로 3d face modeling에서 데이터는 3d face를 scan한 set으로 구성된다. 이러한 3d facial shape과 texture( 혹은 color )의 statistical model이 3dmm이다. 즉, 3d facial shape이나 texture를 이용해서 새로운 3d shape과 texture를 가진 face를 만들어낼 수 있도록 모델링해주는 통계적 방법인 것이다.
- 결국은 통계적 모델링이니 3d shape들과 texture들을 vector sapce에 매핑을 해주고, vector space에서 각각의 shape과 texture가 특정 vector를 의미하게 된다면 이러한 shape과 texture vector들의 linear combination을 통해서 새로운 face의 shape, texture도 모델링해줄 수 있다는 것이다. 하단의 Figure는 이러한 의미를 잘 설명한다.


- 좀 더 자세히 살펴보자면 앞서 말했듯 3d scan data를 사용한다. 즉, 다음과 같이 scan된 face data들(S_i)이 여러 개 있을 때 각각의 shape을 shape vector로 정의한다. 각 shape vector는 scan된 data에서 여러 개의 vertex를 샘플링해서 구성하게 되고, 다음과 같이 x, y, z 가 하나의 vertex를 의미하며 이것이 반복되어 하나의 shape vector가 만들어지게 된다. 참고로 texture vector는 각 vertex부분의 RGB Color값이 담겨있는 texture mapping이라고 생각하면 된다. 즉, 각 shape과 texture vector는 각 componenet(=point=vertex)는 position x, y, z와 color R, G, B를 묘사한다는 것이다.
- 그래서 결국 이렇게 충분히 많은 shape들이 scan되어 존재한다면 해당 vector space에서 우리가 가지고 있지 못한 shape vector라도 이미 존재하는 shape들의 linear combination을 통해서 만들어낼 수 있다는 것이 3dmm의 메인 아이디어다.
- 이해가 잘 안된다면 선형대수를 떠올려보면 된다. 선형대수에서는 vector space에서 새로운 vector들을 만들 때 기존의 vector들의 적절한(각각의 vector들의 weight를 어떻게 설정하는지에 따라서) 선형 결합을 통해서 표현된다.
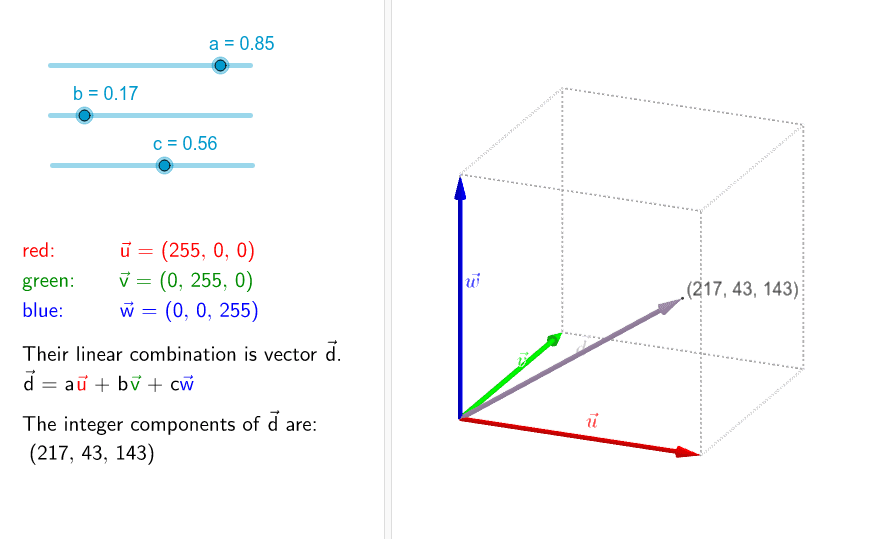
- 따라서 이러한 3dmm이 모델링 된다는 것은 new instance face들을 잘 만들어내는 morphing을 하는 것이고, 결국 capture되어 데이터로 존재하는 각 shape or texture vector들의 linear combination의 coefficient혹은 weight가 적절히 설정되면서 새로운 face를 만들어내게 되는 것이다. 이때 weight 값들이 learnable parameter라고 생각하면 되겠다.
- 물론 이 때 주의할 점은 3dmm은 point-to-point correspondence한( 모든 individual face들 간의) space에서 facial shape과 texture를 모델링하는 것을 학습하는 것이다. 이게 무슨 말이냐면 한 face의 코에 해당하는 point는 다른 face의 코에 해당하는 point아와 correspondence 해야 한다는 것이다. 즉 하나의 vertex i는 항상 같은 구조의 point를 표현해야 한다는 것이다. S_1의 vertex i와 S_n의 vertex i가 동일한 structure상에서의 point를 의미해야 한다는 것이다.
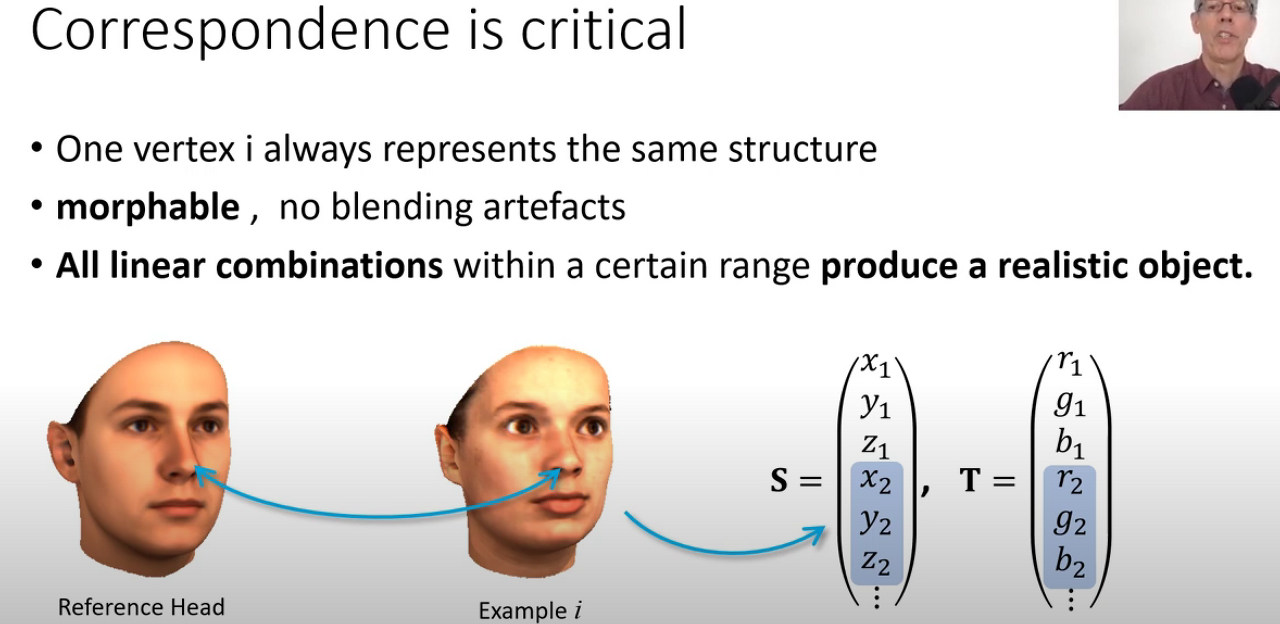
- 이렇기에 3dmm은 새로운 instance of faces를 만들어내게 해주는 것이다. 그 과정이 morphing이라는 형상변형을 통해서 되는 것이고, face들의 타입 간에도 근본적인 transformation이 가능하다. ( Image Editing에 대한 background가 있다면 2d image에서 pose를 바꿔주거나, 성별 등을 바꿔주는 것과 같은 맥락의 transformation을 3d에서 하는 것이라고 생각해도 좋다. ) 그렇게 새로운 성별 혹은 새로운 얼굴형을 가진 new face를 모델링할 수 있게 되는 것이다. 하단의 영상을 다 보면 좋고, morphing에 대한 감을 잡고 싶다면 1:08초 정도부터 봐도 좋다.
https://www.youtube.com/watch?v=MlGkzFeyCYc
- 물론 linear combination을 통해서 new face를 만들어내는 것 외에도 (연장선상에 있지만) gender와 같은 attribute를 manipulating하거나, animation을 만들거나, image로부터 3d reconsturction을 하는 것 등도 3dmm의 주요 목적들이다.
Approach to 3DMM
- 3DMM 에 대한 Classical Approach는 PCA와 같은 dimension reductoin을 통해 supervison했었다. 예를 들면 vector space의 Principal Component들을 원하는 Variance의 개수만큼 뽑고 이는 shape의 가장 variation이 큰 pricinpal component이니 이 방향을 축으로 변화해가면 morphing이 가장 잘 보인다는 것이다.

- 하지만, 이러한 linear model과는 다르게 non-linear transformation을 통한 morphing을 하는 것이 우리가 원하는 대로 컨트롤하기에도 shape, texture 등의 표현력 측면에서도 훨씬 좋은 결과를 가져왔기에 점차적으로 Deep Learning의 영향을 받게 된다.
- 딥러닝 기반의 방식은 일반적으로 face image를 input으로 DNN을 통과시켜 shape과 texture에 대한 파라미터를 뽑게 하고, 이를 각각을 decoding해주는 decoder를 통해 shape 및 texture를 estimation해주는 방식이었다. 즉 기존의 shape, texture vector를 가지고 있는 상태에서 input image에 기반해서 새로운 shape, texture, lightning등의 파라미터를 인코더를 통해 뽑아내게 되고, 이들은 decoder를 통해서 face skin texture나 3d face shape(mesh)를 만들어내게 된다. 그 결과들은 differentiable rendering layer를 거쳐서(learnable한게 아니고 differentiable) 렌더링되어 하나의 이미지가 나오게 된다.
- 사실 하단의 예시는 좀 복잡한 편이다. 결국은 3dmm에서의 learnable parameter인 shape weight와 texture weight같은 것을 Neural Network를 통해 뽑고, 이를 다시 Neural Network를 통해 디코딩해주는 결과 값을 렌더링해서 원하는 결과와 매칭을 통한 loss를 measure해 학습을 한다는 것이다. 딥러닝을 사용하는데에도 워낙 다양한 방향성이 존재하니 다방면으로 찾아보기를 바란다.
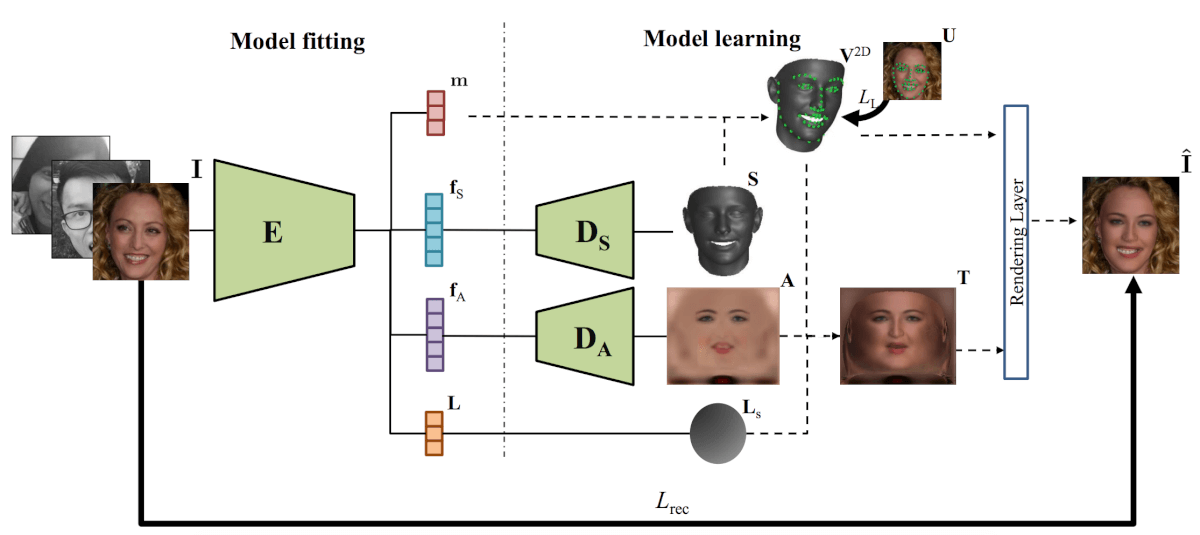
3D Reconstruction
- 3d reconsturction 또한 mian stream에 있는 task이기에 3dmm을 어떻게 활용하는지 간단히 살펴보자. 다음과 같이 random값의 상태에서 3dmm을 통해서 input 2d image의 3d modeling을 뽑아낸다. 그러면 이렇게 뽑아낸 3d model을 기존의 input image와 유사하게 pose를 맞춰주는 등 non-linear optimization을 계속 iterative하게 해주면서 synthetic image와 input image가 유사하게 만들어줄 수 있게 된다. 해당 부분은 아래 클립에 너무 잘 나와있기에 꼭 확인해보면 좋겠다.
https://youtube.com/clip/Ugkxtwf9fJF4Saf1Rzs5mn-iq2DsUkSpzMF0

References
- https://www.youtube.com/watch?v=UGtIwWv1dds
- https://www.youtube.com/watch?v=MlGkzFeyCYc
- https://neurohive.io/en/state-of-the-art/learning-3d-face-morphable-model-out-of-2d-images/
'Concept > Computer Graphics & 3d Vision' 카테고리의 다른 글
| [Concept] 3D Aware Image Synthesis ( or 3D Aware GAN ) (0) | 2022.11.16 |
|---|
