
3d aware image synthesis란?
3d aware image synthesis란, image synthesis를 함에 있어서 3d aware 한 정보들을 학습함으로써 합성해내는 이미지들이 3d 공간의 정보와 consistent 하게 image를 합성하는 task입니다. 다시 말해 2d image들로부터 unsupervised하게 neural scene representatoin을 학습해 3d aware image를 합성하는 것입니다.
기존의 이미지 합성 분야에서 GAN 혹은 adversarial training방식은 다양한 image synthesis task들(Image Generation, Image to Image Translation, Image Editing)의 상당한 발전에 큰 기여를 했습니다. ( 물론 기존의 VAE나 최근 엄청난 영향력을 행사하고 있는 Diffusion도 마찬가지입니다.) 하지만, 대부분의 기존 연구들은 오로지 2d pixel space 위에서 이루어졌습니다. 즉, 현실인 physical real world의 3차원적인 특성들은 무시되고 있던 것입니다. 그렇기에 기존의 연구들에서 2d gan으로 충분히 high quality의 이미지를 만들어내는 데에는 성공했지만, 3d aware 한 정보들은 학습하지 못했기에 image editing이나 view synthesis와 같은 분야들에서 application에 제한적이었습니다. ( 실제 현실은 3d이니까요 )
예를 들어 봅시다. 사람의 얼굴을 생성하도록 잘 학습된 생성 모델이 있습니다. 이 모델은 StyleGAN의 영향을 받아 feature간의 disentanglement를 고려한 모델입니다. GAN 그리고 이어지는 task인 Image Editing을 살펴보면 Latent Sapce Editing을 통해서 특정 semantic feature를 바꾸는 방식입니다. 여기서 semantic feature를 다른 camera view 혹은 camera pose 등으로 생각해봅시다. 어떤 결과들이 나올까요? 무척 poor 한 결과들을 얻게 됩니다. 즉, 3d aware 한 정보가 필요한 semantic feature or attributes를 제대로 학습하지 못한 것입니다. 당연하게도 2d pixel space의 이미지들만으로 학습했기 때문입니다. 즉, 3d aware information 없이는 camera pose를 바꾼 상황으로의 변환 등에의 attribute 통제에 한계가 존재할 수밖에 없다는 것입니다. 하단의 figure를 보시면 와닿을 것 같습니다. 두 샘플 모두 생성된 이미지의 camera pose를 latent navigation 한 결과입니다. 단순히 camera pose만 변경하고 싶은데 생성된 샘플의 identity까지 변환되는 모습을 볼 수 있습니다. ( 다른 사람이 되거나, 의자의 content자체가 바뀌는 모습 )


위 예시 내용을 다시 정리하자면 3d aware한 정보가 부족하기 때문에 3d aware attribute와 기존의 다른 attribute들 간의 disentanglement가 되지 않는 즉 entangled 된 상황이라고 정의할 수도 있습니다. 즉, 3d aware information의 부재로 인해 다른 2d aware attribute들과 disentanglement 하는 데에 한계가 있는 것입니다. 3d aware gan은 구조적인(3d aware) 정보들로부터 identity를 분리함으로써(disentangled) multiple pose들에서 single instance를 렌더링할 수 있는 모델을 만들게 됩니다.
3d aware image synthesis의 연구 동향
Previous Methods ( explicit representation , 2d projection, .. )
기존의 3d aware image synthesis에서는 3d structure of objects를 잘 이해하고 이미지를 synthesize하도록 모델링을 하기 위해서 explicit representation을 많이 사용했습니다. ( volume representation, mesh, point cloud 등등 ) 그러나 이러한 생성모델들은 photorealistic 3d training data의 부재와 single object's multiple view synthesizing을 못함 등의 문제로 인해 제한적이었습니다. 크게 Voxel based와 Convolutional based로 나눌 수 있는데, Voxel based같은 경우 voxel의 특성상 coarse detail을 잘 잡아내지 못하고 computational complexity로 인해 low reolution까지만 가능하게 제한적입니다. Convolutional based같은 경우에는 finely detailed image를 만들어낼 수 있지만, black box rendering을 학습하는 것이기에 multi view consistency가 보장되지 않습니다. 또한, 뒤에서 잠시 언급할 학습 데이터셋의 분포에 현저히 적은 camera pose들은 무척 못하는 등의 generalization이 어려운 모습을 보입니다. ( 반대로 Voxel based는 그래도 voxel에 기반하니 interpretable하다. 즉, view consistency도 가능하다 등으로 이해할 수 있을 것입니다. ) 즉, 이러한 기존의 방법론들은 Fidelity, High Resolution Synthesis, fine detail 등 특정 부분에서 유독 약한 모습을 보였습니다.
또한, Neural Rendering을 사용하는 기존의 방법론들도 있었습니다. 하지만, 이러한 방법들은 대부분 3d를 2d로 projection하는 방식이었습니다.( 지금도 마찬가지입니다. ) 다만, 당시의 방법론들은 매우 간단한 projection을 사용했습니다. 그렇기에 학습데이터셋의 pose를 충분히 representatoin하지 못했습니다. 즉 표현력이 부족했습니다. 그렇기에 유독 학습데이터의 분포에 종속적이게 되어 학습데이터 분포에 존재하지 않는 3d aware한 정보를 잘 학습하지 못했습니다.( HoloGAN 참조 ) 그럼에도 불구하고 이러한 Neural Rendering기반의 방법론들은 camera parameter인 camera pose, focal length, aspect ratio 외에도 다른 파라미터들을 explicit하게 control할 수 있었기에 많은 관심을 받았습니다.


view attribute disentanglement
이는 NeRF의 등장으로 새로운 국면으로 접어들게 됩니다. NeRF를 통해 얻을 수 있는 3d aware한 정보는 view 혹은 camera pose에 대한 정보입니다. 즉, NeRF를 통해 rendering 되는 결과들은 모두 view consistent 한 특징을 가지게 됩니다. 이를 활용해 3d aware image synthesis에서는 3d aware attribute인 camera pose( view )를 다른 attributes와 disentanglement 하도록 학습합니다. 즉 NeRF가 센세이션 하게 영향력을 행사하면서 3d aware image synthesis에서도 3d aware information들 중 view로 접근하게 된 것입니다. 즉, 기존의 2d generative model들은 3d information을 고려하지 않기에 camera pose를 바꿨을 때 합성되는 이미지의 결과들이 왜곡되는데 3d aware representation을 학습하게 함으로써 기존의 identity를 왜곡하지 않게 ( disentanglement 하기 때문에) 즉, view consistent 한 high quality의 이미지를 합성하도록 하겠다는 것입니다.
이러한 3d aware image synthesis에 대한 연구는 일반적인 생성모델 연구의 main stream처럼 주로 사람의 얼굴 데이터셋인 FFHQ, CelebA등에 대해서 많이 이루어졌습니다. 일반적인 Human Face 데이터셋에서 주로 확인되는 문제는 데이터셋의 분포의 한계입니다. 얼굴 데이터를 수집함에 있어서 다양한 view 분포에 대한 고려가 적을뿐더러, 사람을 위아래에서 찍는 경우가 일반적이지 않다 보니 학습 데이터셋에는 camera pose가 위아래로 있을 때의 데이터가 현저히 적습니다. 생성 모델은 학습 데이터셋의 분포를 학습하다 보니 학습 데이터셋에 적은 분포인 위아래에 camera pose가 놓여있는 등의 image synthesis 또한 제대로 되지 않는 것입니다.

이러한 문제 상황을 학습 데이터셋 분포에서 벗어나 NeRF의 아이디어를 도입해 view consistent한 이미지를 만들어내게 학습함으로써 다양한 view에서의 synthesis도 잘할 수 있게 하자는 것이었습니다. 결국 핵심은 3d aware image synthesis의 최근 main stream은 NeRF를 활용해 implicit 3d scene representation을 2d image들로부터 학습해 multiview consistent image synthesis를 하도록 하는 것입니다.( 즉, 이렇게 학습된 representatoin은 new camera pose로 부터 view consistent한 image들을 render할 수 있도록한다는 것입니다.) 즉, 이렇게 implicit radiance field를 학습함으로써 근본적인 3d structure-aware representation을 학습하도록 NeRF를 도입했고, 이 또한 neural rendering이기에 기존의 neural rendering 방법론들이 가지는 explicit camera control이라는 큰 장점도 그대로 가지고 있어 view consistent image synthesis도 가능하다는 것입니다. 이러한 explicit camera control이 가능하기에 학습 시에 보지 못했던 pose들과 같은 3d aware한 정보도 반영할 수 있고, 기존의 black box방식과는 다르게 interpretable하다고 할 수 있는 것입니다. ( camera control을 통해 원하는대로 rendering가능 )

하지만, 이러한 implicit neural representation을 사용하는 경우에도 아직 fine detail을 잘 잡아내지 못한다는 문제를 가지고 있었습니다. 이는 최근 pi-GAN을 필두로 EG3D와 같은 좋은 논문들이 많이 나오면서 fine detail을 아주 sharp하게 잘 잡아내며 해결되었습니다. 3d aware image synthesis는 더 나아가서 facial expression이나 facial shape과 같은 추가적인 3d information까지 기존의 2d aware attribute들과 분리해서 잘 반영하도록 연구를 진행하고 있습니다. ( Exp-GAN -ACCV '22 Oral 참조 )
3D Aware GAN
그렇다면 어떻게 이러한 multi-view consistent한 image synthesis가 가능해지는 것일까요? 최근 Diffusion Model이 각광을 받으며 DreamFusion 논문이 나왔듯 3d aware image synthesis에서 diffusion model을 사용하려는 노력도 보이고 있습니다. 하지만, 아직까지 3d aware image synthesis의 주 생성 방법론은 GAN이기에 3d aware GAN을 통해서 설명해보고자 합니다.
아시다시피 NeRF는 single scene object에 대한 multi view image를 input으로 사용해 해당 single scene을 이해하는 모델입니다. 이와는 다르게 3d aware image synthesis에서 하고 싶은 것은 single scene이 아닌 multi scene에 가깝습니다. 즉, 한 사람(identity가 unique)의 얼굴 scene을 완전히 이해하는 모델을 학습시키는 것이 아닌 다양한 얼굴 scene을 3d aware 하게 생성해내고자 하는 것입니다. 이는 하나의 얼굴에 overfitting 시키는 NeRF와는 완전히 다릅니다. 명확히 이해해야할 것은 결국 3d aware gan도 그저 GAN일 뿐이고 이 과정에서 3d aware 한 정보 학습을 위해 NeRF를 일부 사용하는 것이죠. ( 물론 엄청 많은 사람 얼굴들에 대해서 각 사람마다 multi view images이 있는 데이터가 있다면 또 다른 방식으로 가겠지만, 다양한 사람 얼굴들에 대해서 multi view image들까지 모두 갖춘 데이터셋을 구축하는 것은 사실상 불가능합니다. )
결국 2d image들로부터(모든 single object들로부터) unsupervised하게 (GAN ) neural scene representation을 배우는 것입니다. 다시 말해 기존의 FFHQ와 같은 그저 2d image들만을 학습에 input으로 사용해서 3d aware 한 image들을 output으로 합성해낸다는 것입니다. 어떻게 이러한 학습이 가능한 것일까요?
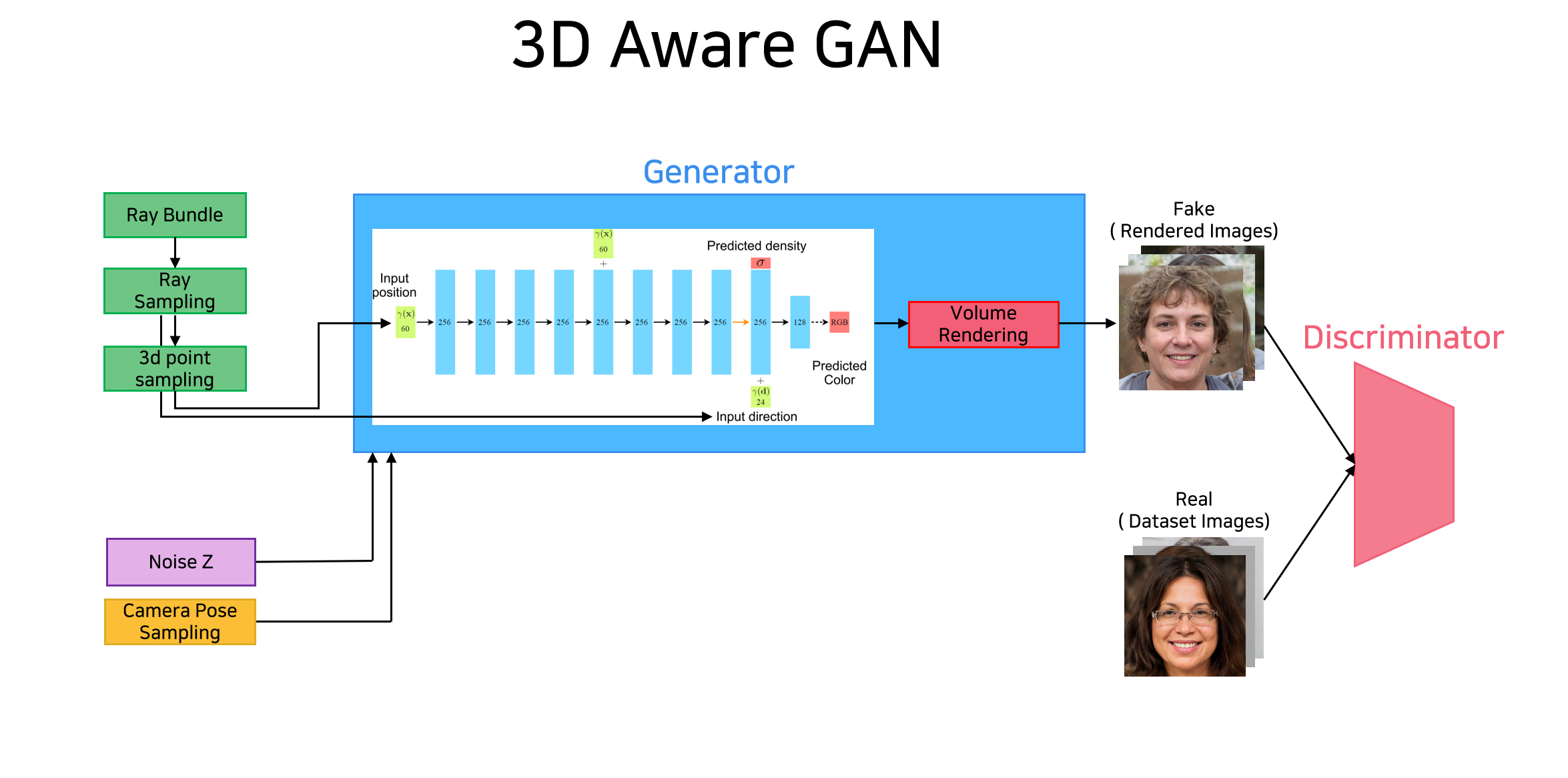
아이디어는 간단합니다. 우선 Adversarial Training을 함에 있어 NeRF를 Generator처럼 사용합니다. 이는 generator가 3d aware한 이미지를 생성할 수 있도록 합니다. Generator에 NeRF의 아이디어를 활용함으로써 생성되는 이미지가 3d aware한 정보를 학습해 view consistent(NeRF처럼)하도록 하는 것입니다. 그렇게 되면 당연히 view의 camera pose를 조절해줌으로써 같은 identity에 대해서 다양한 view에서 찍힌 이미지 또한 합성할 수 있게 될 것입니다.
동시에 GAN처럼 random noise를 implicit feature filed로 mapping을 해줌으로써 identity에 따라서 multiview consistent한 이미지를 생성할 수 있게 되는 구조를 가집니다. 즉, random noise가 바로 3d scene( 브루스 월리스 인지 니콜 키드먼인지 결정 ) 혹은 Identity를 결정할 수 있도록 합니다. 이는 마치 conditional gan에서 생성되는 이미지가 가질 조건(숫자 2이지 3인지)을 주는 구조를 latent vector 하나가 unique 하게 generated image를 결정하는 maaping에 가져와 다음과 같이 random noise가 condition으로 들어가며 이 noise에 따라서 unique 하게 생성되는 이미지의 identity 즉 해당 3d volume이 결정되도록 합니다. 기존의 2D GAN들이 latent vector로부터 directyle하게 2d image를 생성하던 것과 다르게 latent vector혹은 noise를 generator인 implicit neural radiance field의 condition으로 준다는 것입니다.
이러한 구조를 가지기에 NeRF의 구조를 활용해 3d aware한 image를 합성할 수 있는 것입니다. 즉, 이렇게 되면 다음과 같이 특정 identity를 가지는 이미지를 생성할 때 3d aware 하므로 다양한 view에서 봤을 때의 모습도 합성할 수 있는 것이죠. 혹은 다른 camera pose에서 찍었을 때의 이미지를 확인할 수 있는 것입니다.


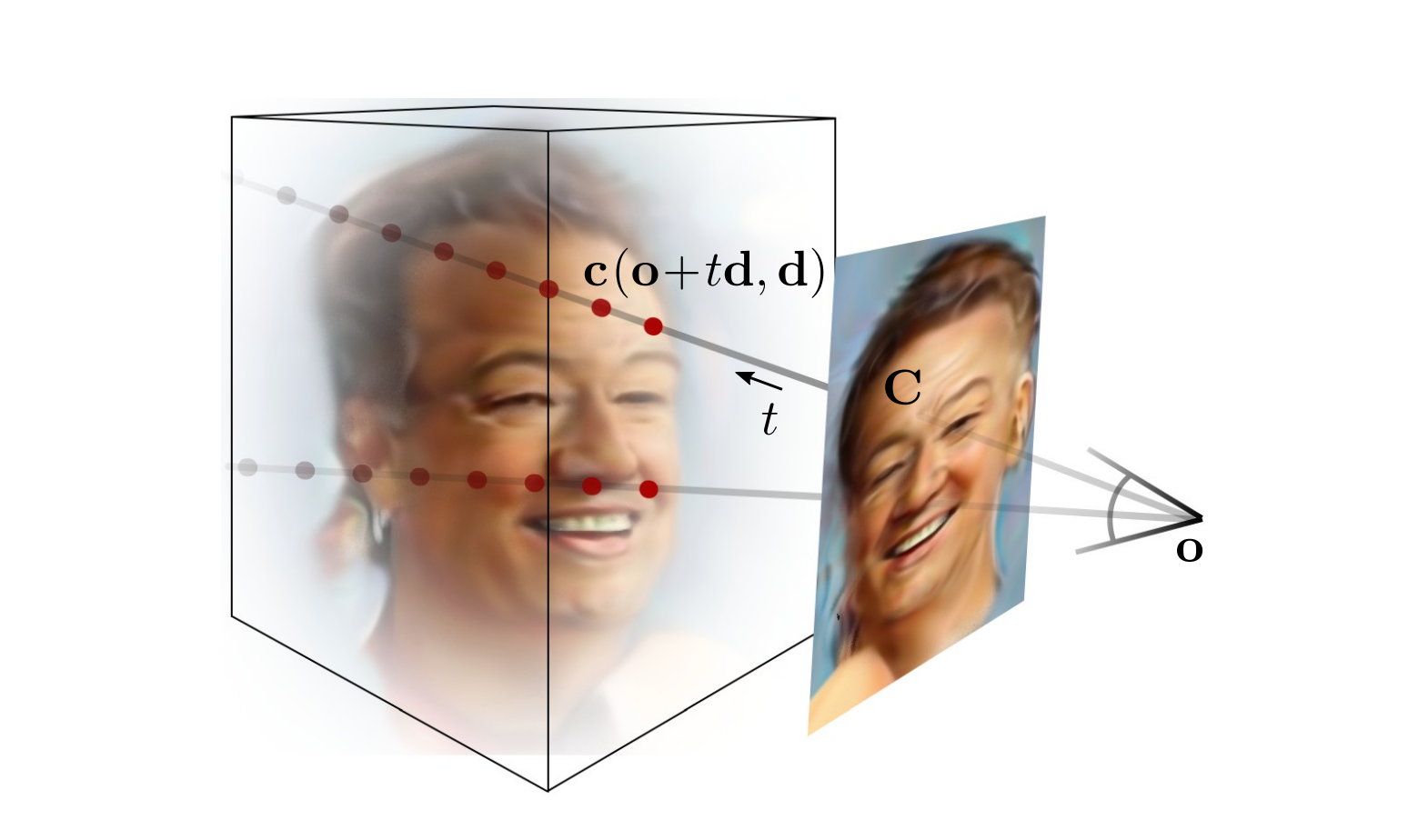
이때 꼭 짚고 넘어가야할 점은 camera pose에 대한 정보입니다. 위의 구조에서 NeRF부분이 제대로 동작해서 multi view consistent 한 이미지가 생성되기 위해서는 다양한 camera pose or view에서의 이미지를 생성해보면서 그게 진짜처럼 생성되도록 학습이 진행되어야 합니다. 즉, image 생성에 있어서 NeRF를 generator로 써서 view consistent의 의미를 살리고 3d aware 하도록 하기 위해서는 학습 중에 camera pose 정보가 필요하다는 점입니다. ( 그 이유는 volume rendering을 걸어서 생성된 이미지로 adversarial training을 하는데 volume rendering을 걸기 위해서 camera pose가 필요하기 때문입니다. ) 일반적으로 NeRF는 입력으로 특정 viewing direction을 가지는 ray위의 sampling points의 x,y,z좌표와 함께 camera pose기준으로 해당 viewing direction을 전달해줍니다. 그렇기에 기존의 NeRF의 경우 하나의 scene에 대한 여러 view 이미지와 각 이미지의 camera pose정보를 같이 입력으로 받게 됩니다. 하지만, FFHQ와 같은 2d image들로 이루어진 데이터셋에 camrea pose정보가 존재할리는 만무합니다. 그렇다면 과연 3d aware gan에서는 이 문제를 어떻게 처리하고 있을까요?
3d aware gan은결국 Generator 부분을 다시 살펴보면 random noise를 image로 mapping 하는 과정입니다. 그렇다면 애초에 이미지를 새롭게 생성하는 것이라면 그 이미지가 어떤 camera pose에 있는지 모르는 것이 당연합니다. 3d aware gan에서는 이 부분을 활용합니다. 즉 생성되는 이미지는 이러한 camera pose에서 찍힌 걸꺼야! 라는 정보를 전달해줍니다. 즉, 랜덤 한 camera pose를 input으로 샘플링해서 전달해주고 이를 받아 생성한 이미지는 해당 camera pose에서 찍은 것처럼 생성되도록 학습하는 것입니다. 이것이 다양한 랜덤 샘플링된 camera pose에 대해서 학습이 되면 view consistent 한 이미지가 생성이 될 수 있게 되는 것입니다. 이렇게 랜덤한 camera pose에서 찍은 이미지를 생성해내고 이렇게 생성한 것이 가짜인지 진짜인지를 실제 데이터셋과 같이 discriminator에 넣어 gan loss에 기반해 학습을 진행함으로써, view consistent 하면서도 진짜 같은 가짜 이미지를 생성할 수 있게 되는 것입니다.
마지막으로 이러한 구조가 어떻게 학습되는지 다시 한 번 짚고 넘어가겠습니다. 앞서도 언급했지만, 결국 3d aware gan은 그저 gan입니다. 그러니 discriminator에 전달되는 것은 image입니다. 따라서 generator에서 나오는 output이 image여야 한다는 것입니다. 하지만, 일반적으로 NeRF를 보면 Network를 통과해서 나온 color와 density값을 volume rendering을 걸어 Radiance 즉 픽셀 하나의 color값을 구하고 이를 GT의 픽셀 하나와 loss를 measure 해 학습하게 됩니다. 따라서 3d aware gan에서는 이미지 사이즈 만큼의 모든 radiance들을 우선 volume rendering을 통해 구해두고 이렇게 rendering 한 이미지 자체를 output으로 보낸 후 이걸 그냥 gt와 measure 하는 것이 아닌 adversarial training을 걸어 학습하도록 하는 것입니다. 그렇게 렌더링 된 가짜 이미지가 진짜 이미지처럼 되도록 학습을 진행한다는 것입니다.
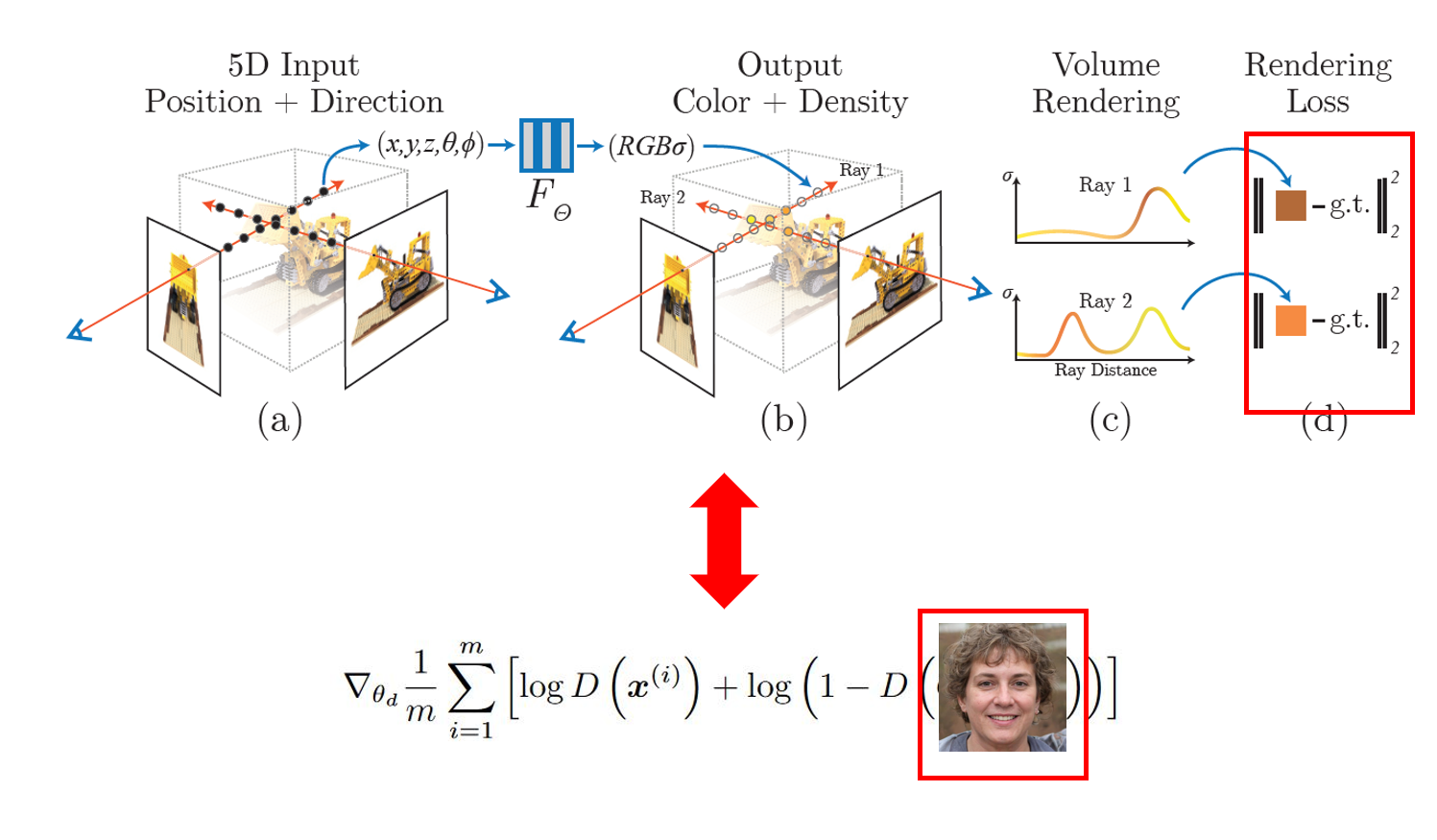
그래서 결과적으로 3d aware gan에서 이해해야할 부분은 크게 두 가지입니다. 또한, NeRF와 비교하면서 어떤 점이 다른지 등을 명확히 이해하는 것이 중요할 것 같습니다. 그래서 결과적으로 3d aware gan은 training time에서는 adversarial training을 위해서 discriminator로 생성된 이미지를 넣어주고, test time에서는 임의의 camera pose를 전달해줌으로써 해당 view의 image를 radiance field가 render하도록 합니다. 이렇게 생성되는 이미지는 당연하게도 view-consistent image일 것이고요.
- 어떻게 3d aware한 정보를 학습하도록 하는지 ( NeRF의 구조를 가진 generator, camera pose sampling 해서 전달 등등 )
- 결국 GAN처럼 동작해야한다는 점
이러한 3d aware gan의 연구들은 주로 대부분 stylegan2의 architecture와 NeRF를 같이 활용하는 방식으로 이루어지고 있습니다. 3d aware gan의 본격적인 시작점에 놓여있는 PI-GAN, 매우 뛰어난 성능을 가져오는 EG3D, 그 외에도 중요한 논문들인 StyleSDF, StyleNeRF 등이 모두 이러한 구조를 가지고 있습니다.
References
- GRAF : https://autonomousvision.github.io/graf/
- pi-GAN : https://marcoamonteiro.github.io/pi-GAN-website/
- EXP-GAN : https://github.com/kakaobrain/expgan
GitHub - kakaobrain/expgan
Contribute to kakaobrain/expgan development by creating an account on GitHub.
github.com
pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
Inverse Rendering and Novel View Synthesis Using a trained π-GAN generator, we can perform single-view reconstruction and novel-view synthesis. After freezing the parameters of our implicit representation, we optimize for the conditioning parameters that
marcoamonteiro.github.io
'Concept > Computer Graphics & 3d Vision' 카테고리의 다른 글
| [Concept] 3DMM : 3D Morphable Face Models (0) | 2022.11.03 |
|---|
