Introduction
- 비디오는 현실의 continous한 visual data를 discrete한 consecutve frame들로 저장하는 방법이다. High fidelity & frame rate을 가진 video를 저장하는 것은 현실적으로 매우 큰 비용이 들기 때문에, 상대적으로 low resolution & frame rate으로 저장하게 된다. ( = limited spatial resolution & temporal frame rate ) 하지만, 이러한 video가 human에게 보여질 때는 high level 정보를 가지도록 복원되기를 원한다.
- 본 논문에서는 이와 같이 space & time 관점에서 high resoluton & frame rate으로 비디오를 복원하는 방법을 Implicit Neural Representation을 활용하는 novel한 방식으로 제시한다. 즉, continuous video representation을 학습함으로써 NeRF처럼 임의의 viewpoint에 해당되는 임의의 frame rate 그리고 임의의 spatial resolution( interpolation or extrapolation )을 복원하게 된다.
Key Idea
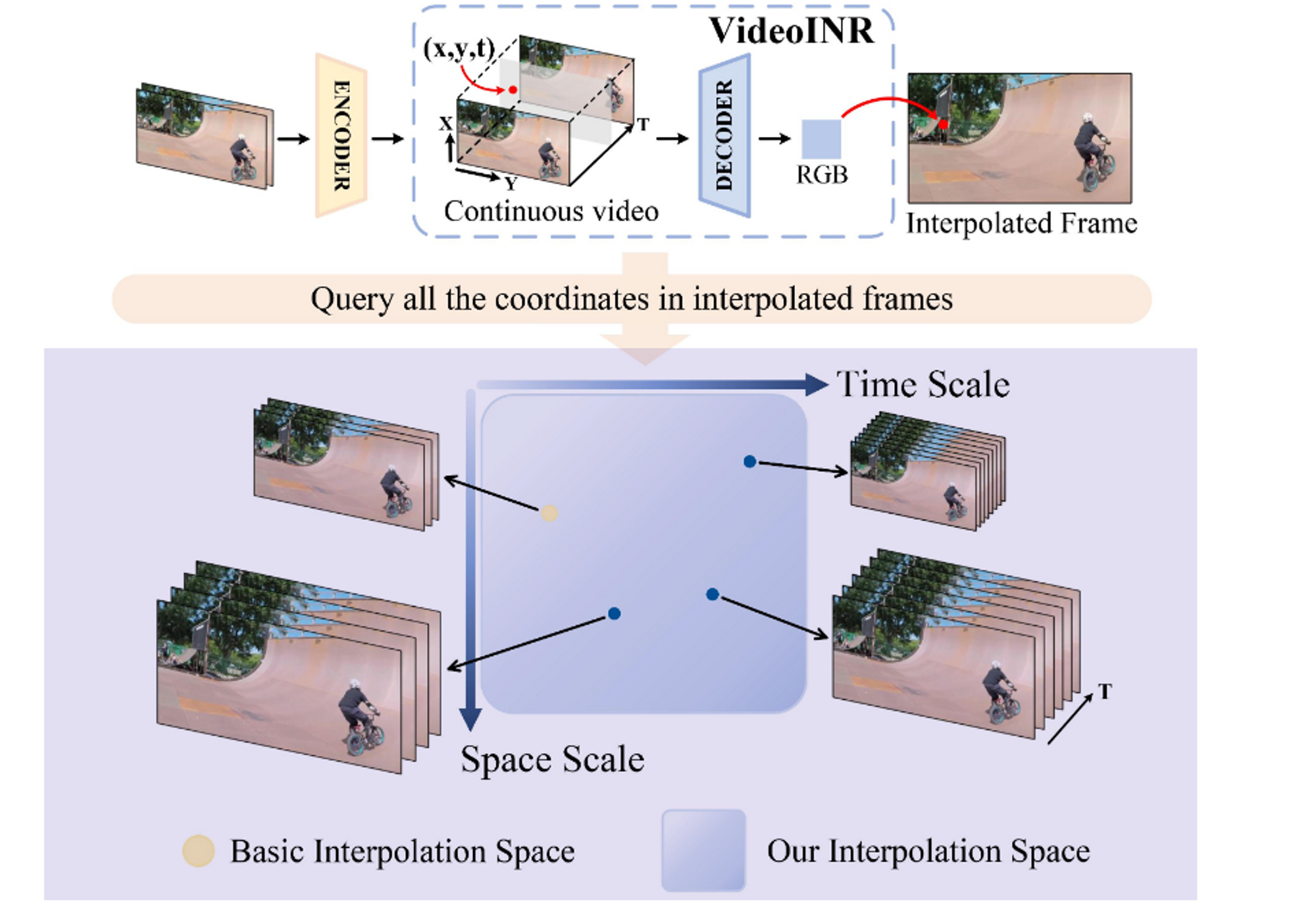
- Learn implicit neural representation which takes a space-time coordinates as input and outputs the corresponding RGB Value. It’s called by continous video representation because sample the coordineate( at time and space )continuously and decode any spatial resolution and frame rate.
- Video INR achieves out-of-distribution generalizatoin at training distributions.

Video Implicit Neural Representation
- 이러한 continuous video representation학습을 위해서 저자들은 implicit neural representation을 사용했다. ( 마치 NeRF에서 new view point synthesis를 하는 것처럼 ) 앞서도 언급했듯 이 neural representation의 핵심은 결국 임의의 space-time coordinate( x_s, x_t) 를 받아서, 해당 coordinate의 RGB value를 get하는 것이다.
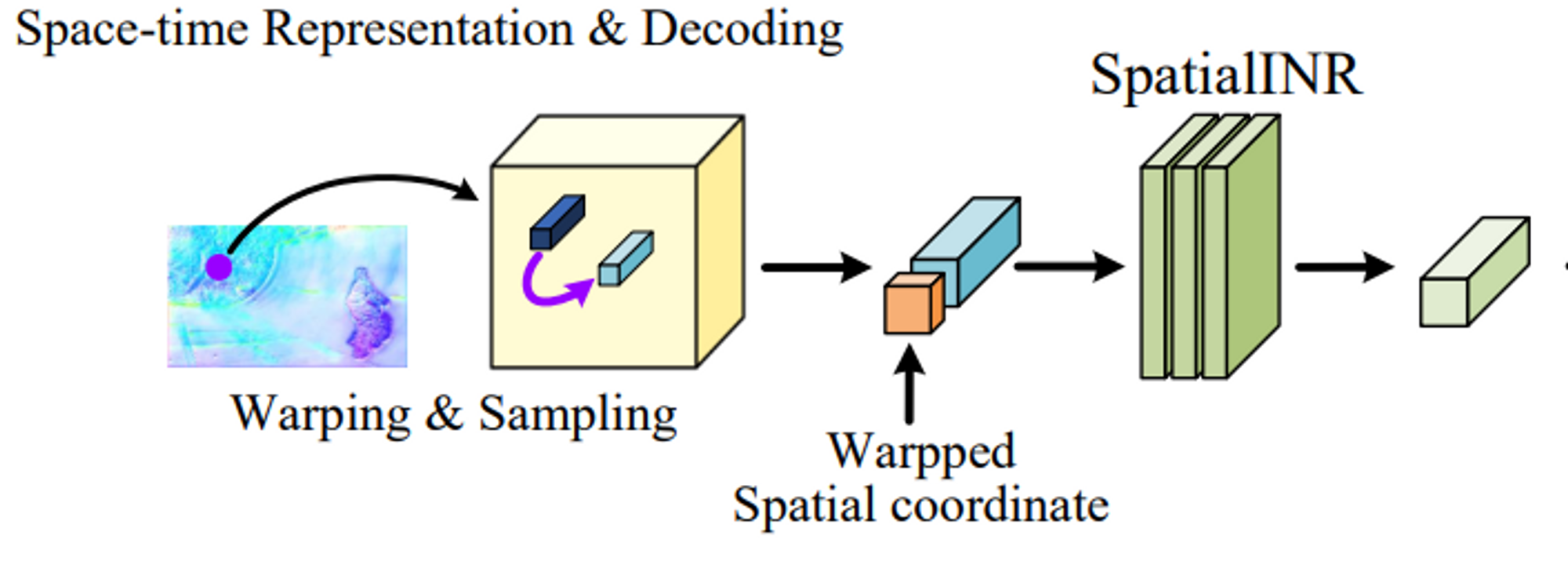
- 전체적인 구조는 다음과 같이 우선적으로 Encoder를 통해서 frature를 input frames에 대해서 추출하고 특정한 Space-time coordinate가 주어질 떄, 해당 coordinate에 대한 feature를 sampling한 후 이를 sptialINR / Temporal INR을 차례로 통과시키며, 임의의 coordinate에 대한 feature vector를 주어진 spatial 정보 혹은 temporal정보에 맞게 만들어내고 이를 통해 얻어낸 condsecutive frame간의 motion정보와 중간에 나온 spatial 정보를 활용해서, motion에 대한 정보를 warping함으로써 원하는 spatial coordinate에 대한 feature정보를 얻게되고 이를 feature를 입력으로 받아 RGB를 만들어내는 decoder를 통과시켜 임의의 위치에 대한 frame 정보를 얻게 된다.
Continuous Spatial Representation
- encoder에 의해 추출된 feature들로부터 원하는 coordinate에 해당하는 (nearest) feature vector를 sampling하고 이를 rrelative position information(feature vector와 query coordinate간의)을 추가해 SpatialINR을 통과시켜 xs 라는 spatial coordinate에 대해서 spatial domain에서 continuous한 feature 를 얻는다.
Continuous Temporal Representation
- Continuous spatial feature를 입력으로 받아 해당 spatial coordinate 즉 위치에서 원하는 time 정보를 condition으로 주고 이를 Temporal IRN에 forwarding을 하게 되면 motion flow정보를 즉 motion pattern을 학습하게 된다. 결국 추가적으로 temporal INR까지 붙여줌으로써 feature의 domain을 2d continuous에서 3d(time추가) continuous로 확장하는 역할을 한다는 것입니다. 동시에 이러한 motion을 이해하기 위해서 continuous motion flow를 output으로 뱉게하는 이유는 VFI관점에서 특정 coordinate의 변화를 학습한다는 관점에서 그런 것 같다.
- motion flow estimation자체는 input으로 consecutive frame들도 넣어줘야하는데, spatial coordinate에 이러한 정보가 녹아들어있다는 관점에서 다음과 같이 수식을 사용하게 된다.
Space-Time Continuous Representation
- 앞서 얻은 두가지 spatial feature 와 temporal feature를 만들어내는 두가지 IRN을 unify시켜야 원하는 RGB value를 얻을 수 있을 것이다. 지금까지 얻은 두가지 otuputs를 이용해서 continouos featrue domain에다가, spatial temporal로부터 얻은 motion field를 warping시킴으로써 warped featrue 즉 contiuous motion ( at space & time )에 대한 정보를 담고있는 warped feature를 얻는다. 이 warped feature는 어떻게 보면, motion field에 의해 만들어진다는 것이 temporal doamin정보를 spatial에서의 motion 즉 변화로 모델링한 것이고 따라서 이를 spatial INR을 다시 통과해 warped된 motion된 새로운 위치에서 정확한 feature를 뽑기 위해서 encoder로부터 만들어진 continuous feature 에 대해 warping시킨 것을 input으로 사용하는 것이다. 그렇게 얻은 frame정보를 활용하면 우리는 space-time coordinate에 해당하는 즉 warped된 coordinates에 대한 feature 정보를 얻게 된다는 것이다.
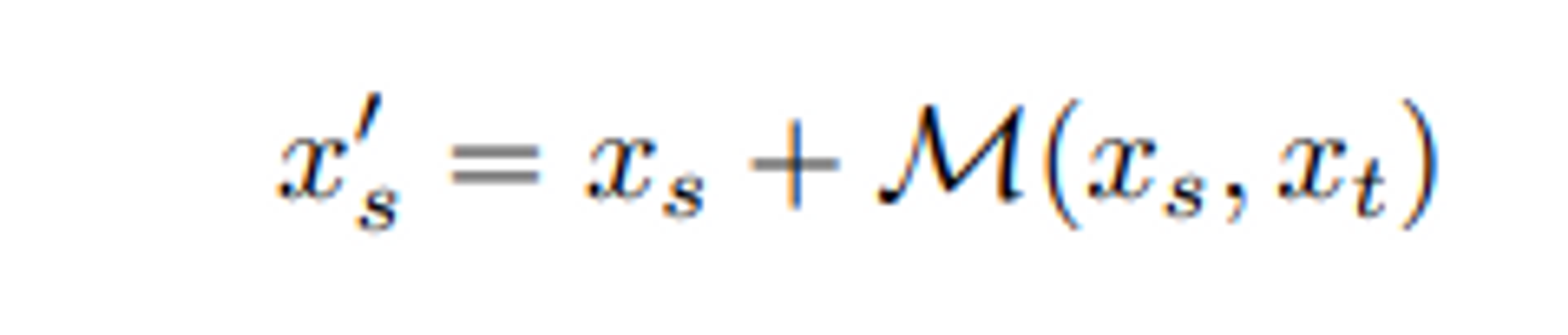
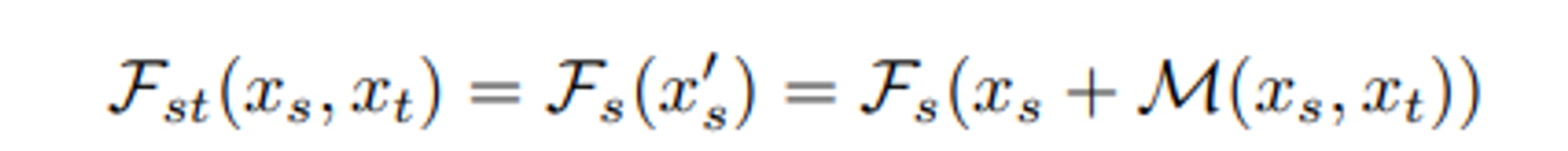
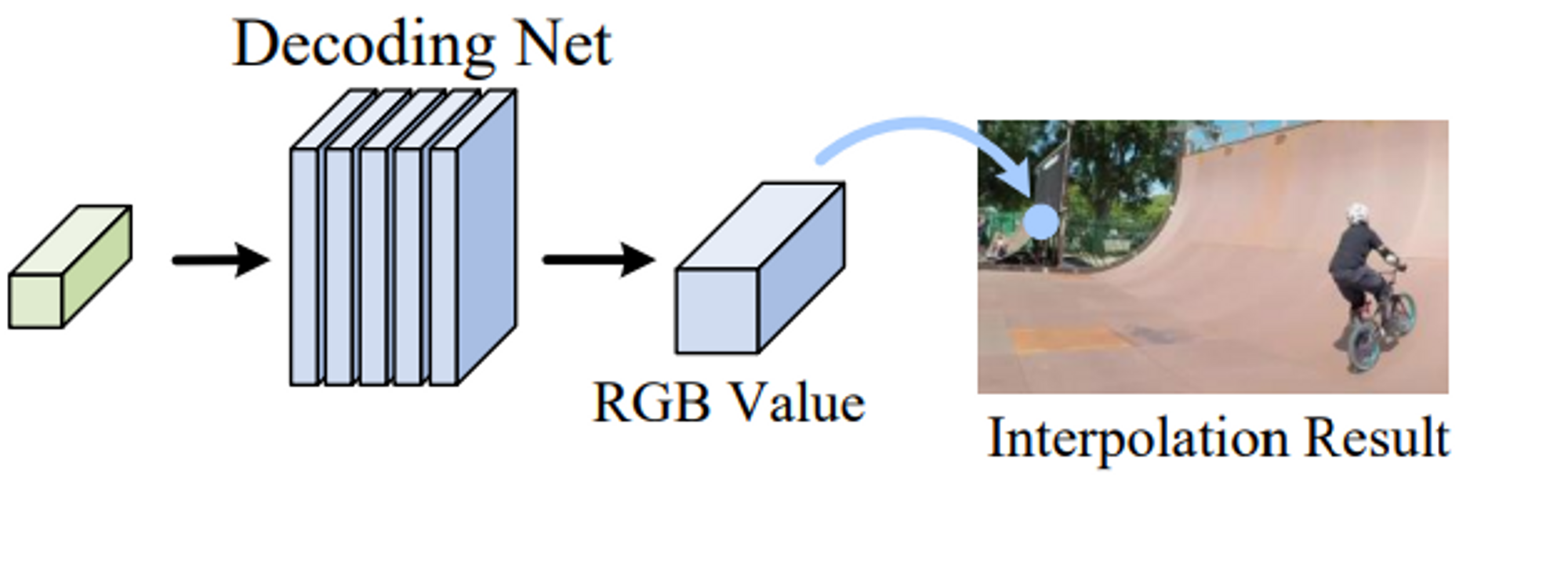
Feature Decoding
- 이러한 featrue정보로부터 RGB를 복원하는 ( NeRF에서 Volume Rendeirng이 하는 역할을 해주는 )역할을 Decoder라는 network에게 넘기게 됩니다.
- 이떄 single feature vector로부터 RGB value를 regressing하는 네트워크이다보니까, different scale에서의 feature들을 결합해주기도 한다.
Frame Synthesis
- 그렇다면 Interpolation ( high resolution & Frame)을 어떻게 진행할까?
- 간단한데, 중간에 우리가 사용하는 continouous feature map을 high resolution으로 만들어주게 되면 일종의 super resolutoin의 역할을 해서 latent hihg resolution interpolated frame을 위한 motion flow field를 생성해 super resolution도 할 수 있다. 이것이 일종의 OOD 역할을 하게 되다.
Evaluation
- 네트워크는 motion을 이해하게 될 것이다. interpolation을 수행하기 위해서
- 이러한 것은 new object appearance등을 제대로 모델링하지 못할 것이라고 생각한다.