이번에는 기존의 GAN Inversion 방법론들이 가지던 문제를 transformer를 통한 새로운 접근 및 해석을 통해 개선하고, Reference-based editing을 위한 네트워크까지 제안한 Style Transformer : Style Transformer for Image Inversion and Editing을 살펴보도록 하겠습니다. 그럼 시작하겠습니다 :)
1. Abstract

본 논문에서는 기존의 GAN Inversion 방법들이 가졌던 distortion-editability의 trade-off 관계를 지적하며 less distortion을 가진 이미지를 생성해내면서도 image editing에서도 flexibility를 가지도록 네트워크를 설계했습니다. 이를 위해 기존의 encoder-based inversion method를 활용하면서 transformer의 아이디어를 활용함으로써 더 좋은 inverted code를 만들어냈습니다. 특히 self-attention과 cross-attention을 통해서 query를 계속 업데이트해나감으로써 inversion의 목적에 부합하는 updated code를 얻어내는 아이디어는 주목할만합니다. 단순히 encoder나 generator에 transformer를 사용하는 것이 아닌 inversion의 목적을 고려해 latent code를 개선해나가기 위해 transformer를 사용한 독특한 방식을 통해 distortion-editability의 trade-off 관계를 개선한 GAN Inversion and Editing Architecture를 제시합니다. 또한, 이러한 아이디어를 활용해 Image Editing에도 사용하면서 Reference-based Editing까지 Image Editing의 영역을 확장해나갑니다.
2. Background
앞서 Abstract에서도 언급되었듯 본 논문은 GAN Inversion 및 Editing의 관점에서 개선 및 새로운 시도가 있는 논문입니다. 따라서 기존의 GAN Inversion 및 Image Editing에 대한 background가 필요합니다. 또한, 본 논문에서는 Transformer의 아이디어를 사용해서 이러한 문제를 해결하기에 간단히 Attention에 대해서 Remind를 하고 가고자 합니다.
2.1. GAN Inversion and Image Editing
2.1.1 GAN Inversion
Why GAN Inversion?
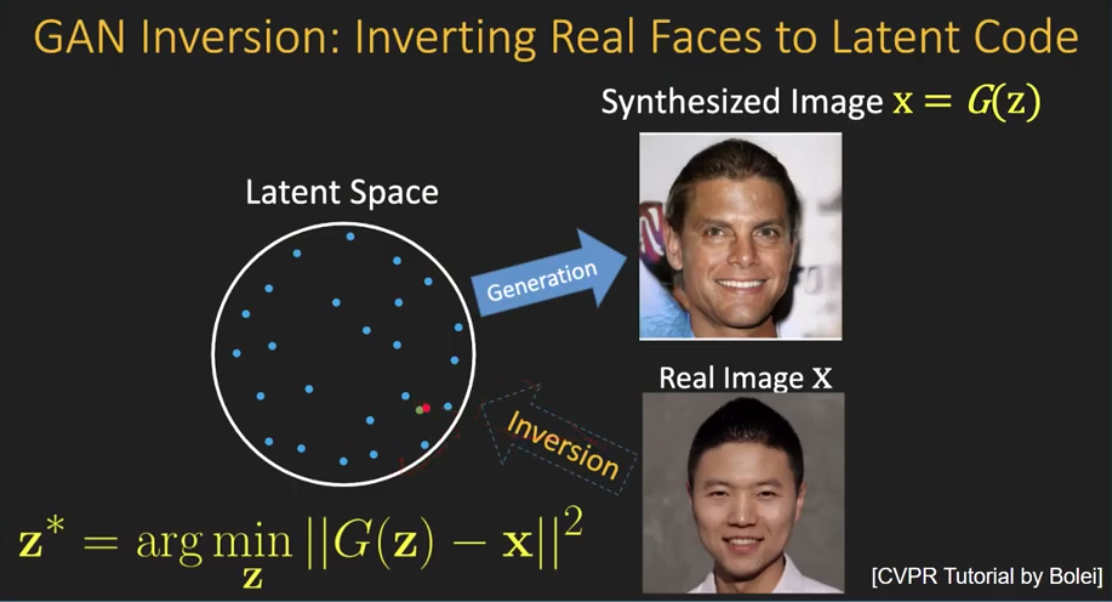
먼저 GAN Inversion에 대해 간단히 살펴보고 가겠습니다. GAN Inversion이란 입력 이미지와 유사한 결과 이미지를 얻을 수 있도록 하는 latent vector를 찾는 과정입니다. 일반적으로 GAN이 학습되면 random latent vector로부터 이미지를 생성해낼 수 있게 됩니다. GAN Inversion은 이의 역과정입니다. 우리가 latent vector를 알기 원하는 이미지를 넣었을 때 GAN의 latent space의 latent vector로 input image를 inverting시키는 것입니다. 그렇다면 이러한 이미지의 latent vector를 왜 알고 싶은 것일까요?
이러한 GAN Inversion은 StyleGAN이 등장하면서 학습된 StyleGAN을 downstream task들을 위해서 사용하는 것이 핫한 연구 주제가 되며 부각되었습니다. 특히 그 중 하나인 Image Manipulation이 크게 주목받았습니다. StyleGAN의 핵심 아이디어인 latent space의 disentanglement는 latent space에서 특정 attribute의 direction만 찾는다면 사용자가 원하는 대로 이미지를 editing할 수 있다고 생각했기 때문입니다. ( 즉, 사용자가 원하는 semantic 정보를 원하는 방향으로 바꿀 수 있다는 것입니다. )
Invert first, Edit later
일반적으로 StyleGAN을 이용하는 image manipulation 방식은 input image를 먼저 원하는 latent space상의 latent vector로 invert해준 뒤에(inverting) 해당 latent vector를 원하는 semantic 변형 방향의 특정 vector를 더해 operation된 latent vector를 만들어내고(editing) 다시 generator에 태워 editing된 이미지를 얻는 방식입니다. 즉, latent vector를 변경함으로써 semantic manipulation을 하는 것으로 특정 이미지를 editing하고자 한다면 해당 이미지를 먼저 latent space로 projection시켜야하고 그 후 target attribute direction으로 modify 시켜줘야 했습니다.
정리하자면 real-world의 이미지가 주어진다면 먼저 해당 이미지의 latnet code를 찾는 inverting step과 이렇게 찾은 latent code를 우리가 원하는 target attribute에 맞게 이동함으로써 edited image를 만들어내는 editing step이 존재하는 것입니다.
따라서 실제로 원하는 이미지를 만들어내거나 이미지를 원하는 방향으로 변화시키는 수요가 존재하는 Practical Domain에서 실제로 GAN이 사용되기 위해서 GAN Inversion의 중요성은 부각되었습니다. 물론 이외에도 StyleGAN 논문에서도 살펴볼 수 있듯이 Fixed StyleGAN을 사용해서 Image Editing을 함으로써 생성 모델의 Quality Evaluation을 하기도 합니다. 따라서 GAN Inversion은 다방면에서 중요한 분야입니다.
Two Methods of GAN Inversion
이러한 GAN Inversion에는 크게 두 가지 방식이 존재합니다. Encoder-free Method 와 Encoder-based Method입니다.
Encoder-free Method
전자가 GAN Invesion의 convnetional한 방식으로 다음과 같습니다. Trainable Parameter가 존재하지 않고 latent vector 자체를 optimizatoin해주는 것으로 예를 들어 reconstruction되기를 원하는 이미지 즉, invert되기를 원하는 input image가 있을 때 랜덤한 latent vector로부터 생성된 fake image가 원하는 input image와 같아질 수 있도록 measure를 한 후에 이걸 최적화하기 위해서 latent vector 자체를 계속 optimization하는 방식인 것입니다.( gradient descnet를 통해서) 즉, 수백 수천번의 multiple iterations를 거치면서 점차 랜덤 했던 latent vector가 generator를 통해서 input image를 reconstruct해낼 수 있는 inverted latent vector로 optimization되는 것입니다.
하지만, 이러한 Optimization을 하는 Encoder-free Method는 복잡한 latent structure를 다루기에 적절하지 못합니다. 또한, multi step iteration을 통해서 좋은 latent code를 찾더라도 한 이미지에 대해서 Inversion을 하기 위해서 multi step iteration을 거쳐야 한다는 것은 무척 비효율적이고, reconstruction loss를 바탕으로 latent vector 자체를 업데이트하는 방식은 editibility관점에서도 접근성이 좋지 않습니다. optimization을 통해서 editing을 하려면 optimization과정에 editing이 반영되어야 하는데, training parameter가 없기에 접근 방식들이 제한적이고 올드합니다.
Encoder-based Method
따라서 이러한 encoder free method의 비효율적인 측면과 editing의 관점에서의 부적절함 때문에 최근에는 대부분의 gan inversion연구가 encoder -based method를 통해서 바로 inverted latent vector를 뱉는 encoder network를 학습시키고 있습니다.( 혹은 두 가지 방법을 합치는 Hybird방식도 존재합니다. encoder 네트워크를 opimization을 위한 좋은 inital point를 찾기 위해 사용하고 나서, 추가적으로 latent vector optimization을 진행하는 방식입니다. )
Encoder-based Method는 애초에 목적 자체가 모든 이미지들에 대해서 inversion을 얻을 수 있게 하고자 했기에 아주 효율적이며( 특히 inference ) trainable parameter를 가진 network를 사용하기에 기존의 다른 정보들을 사용하던 conditional network나 sub information을 사용하는 대부분의 방법론의 아이디어를 사용하기도 쉬워 editing 하기에도 훨씬 용이합니다.
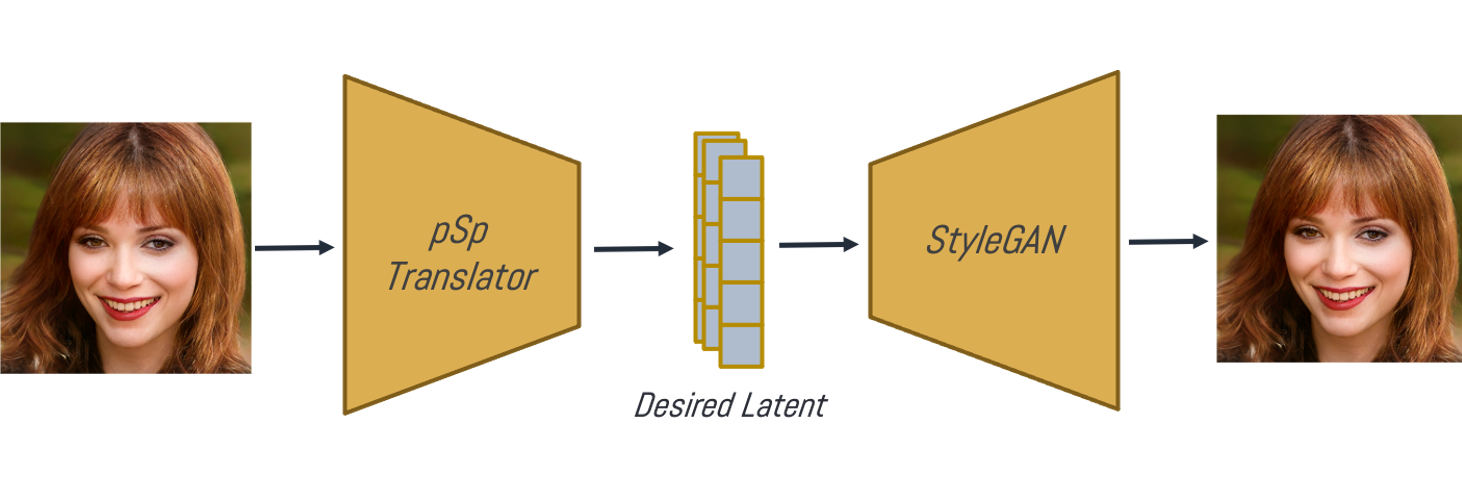
따라서 본 논문에서도 Encoder-based Method를 사용합니다. 하지만, 단순히 encoder-based방식은 아닙니다. 뒤에서 천천히 이전의 related works를 살펴보면서 뭐가 다르고 뭘 차용했는지 왜 그랬는지를 살펴봅시다.
2.1.2. Latent Sapce
GAN을 공부하시면서 StyleGAN을 공부하셨다면 Intermediate Latent Sapce인 W space와 Z space의 차이를 인지하고 계실 것입니다. 그런데, GAN Inversion 분야에서는 주로 W+ Space를 사용하고 있습니다. 앞선 두 latent space들과 어떤 점이 다르고, 왜 이러한 W+ Space를 사용하는지 간단히 살펴보도록 하겠습니다.
StyleGAN and W-space
간단히 stylegan을 다시 보며 W space와 Z space를 리마인드 해보겠습니다. StyleGAN에서 1024x1024의 고해상도 이미지를 만들어내기 위해서 주입해줘야 하는 style vector는 총 18개입니다. 하지만, 기존의 stylegan은 하나의 latent vector를 모두 똑같이 각각 다른 level에 주입해주는 방식입니다. 일종의 복사인 것입니다. 이러한 W space에서 gan inversion을 진행하게 될 경우 어떤 method를 사용하건 1x512짜리의 latent vector를 inverting을 통해서 얻고 이를 18차원으로 복사해 18x512를 stylegan에 주입하게 됩니다.
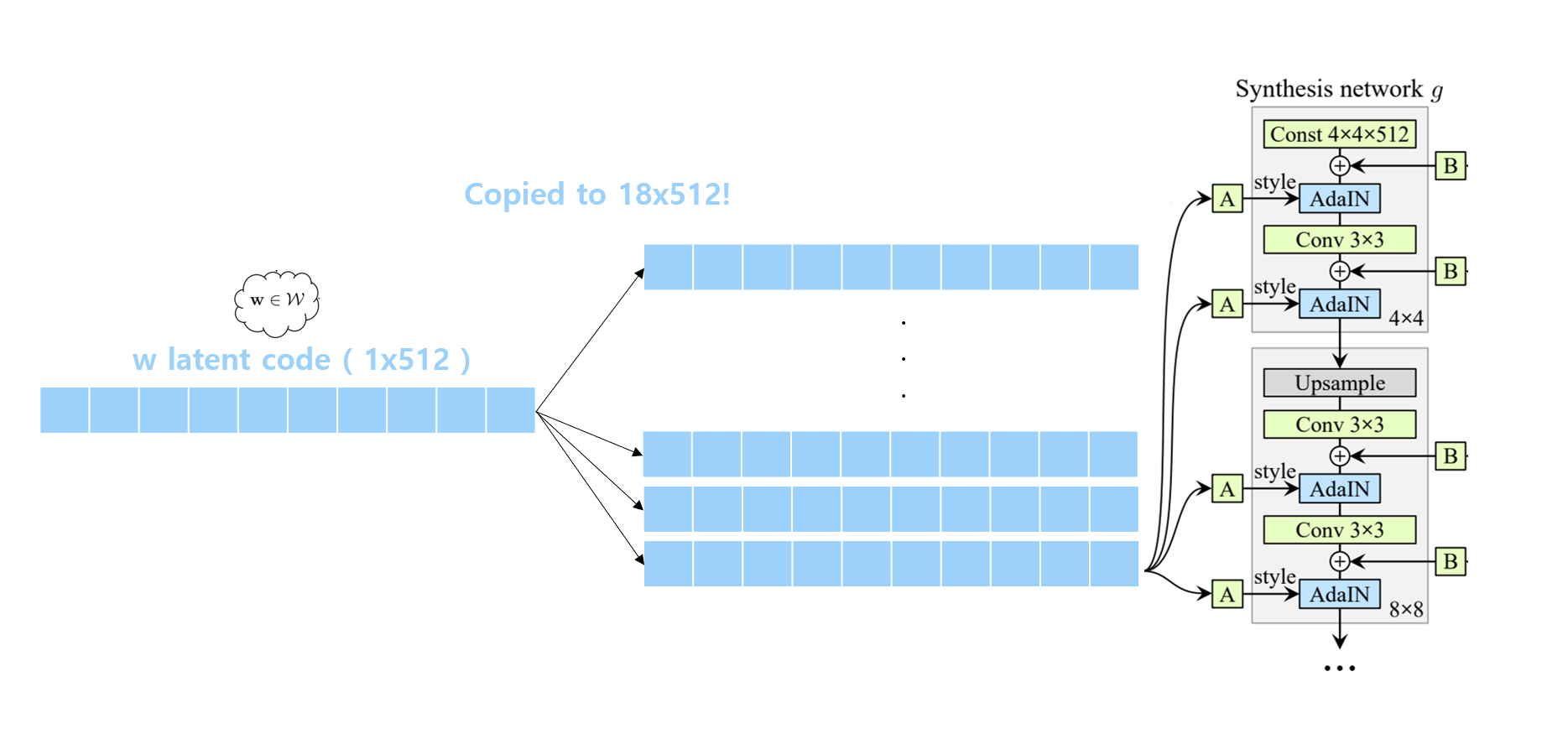
하지만 GAN Inversion의 등장 배경을 고려할 때 학습에 사용한 이미지뿐 아니라 그 외의 이미지들까지 넣어 더욱 높은 표현력이 필요한 상황에서는 오로지 1x512 vector를 복사해서 사용하는 것은 너무 많은 generalization이 이루어져 실제로 reconstruction시 artifact가 생기거나 평균에 가까운 이미지들을 만들어내려고 하는 등의 문제가 발생하였습니다. Generator를 학습하는 과정이라고 할 때는 오히려 너무 많은 latent vector의 다양성이 불필요할 수도 있지만, gan inversion같은 경우 현실의 더 많은 이미지들의 정보를 잘 이해해야 하기 때문에 더 높은 표현력이 필요하고 디테일들을 잡을 수 있어야 합니다.
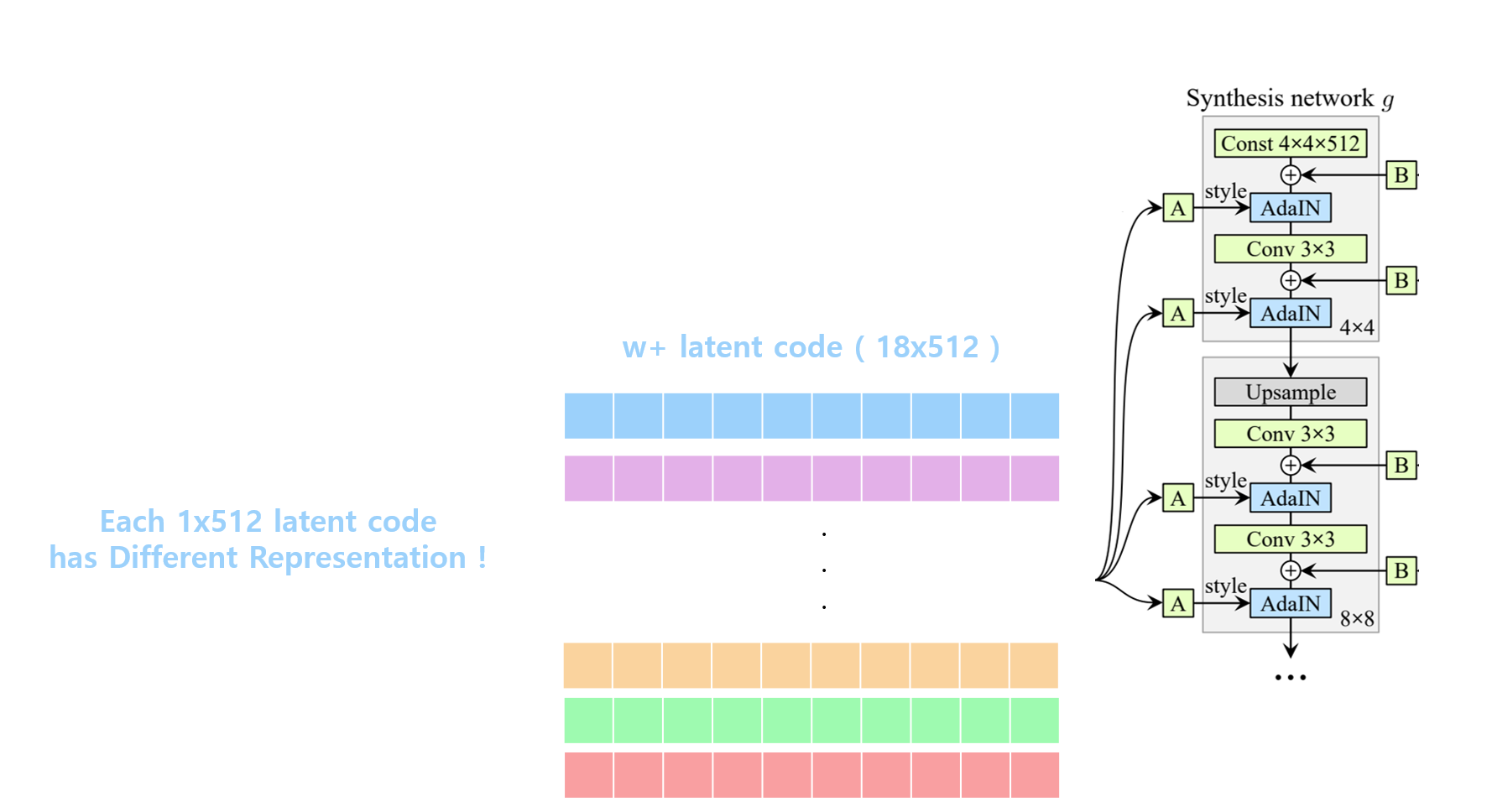
이러한 배경에서 나온 것이 W+ Space입니다. 개념은 간단합니다. W+ latent space는 w space를 확장한 것으로 18개의 latent vector가 1x512 vector를 복사하는 것이 아닌 모두 다른 512차원의 latent vector가 18개인 latent space를 의미합니다. 즉, StyleGAN에서 generator에 들어가는 18개의 512차원 latent vector들을 모두 optimization한다면 즉, 전부 개별적으로 업데이트가 된다면 표현력이 더 높아지고 각각의 level에서의 디테일들을 더 잘 이해할 수 있기에 reconstruction quality가 더 높아질 거라는 겁니다. 즉 W+ Space에서는 각 이미지가 18개의 다른 level에서의 different codes에 의해서 representation된다는 것입니다.
Editing in W+ Space
Editing에 관점에서도 마찬가지입니다. 당연하지만, StyleGAN에서도 살펴볼 수 있듯이 Z-Space에서의 editing은 가우시안 분포로 한정된 공간이기에 semantic manipulation이 원하는 대로 이루어지기 어렵습니다. ( StyleGAN 리뷰 참고 ) 따라서 StyleGAN에서는 W sapce를 제시했는데 이는 위에서도 언급했듯 18개로 복사되어 각 level에 주입됩니다. 일반적으로 1x512의 w latent code하나만으로 수많은 이미지들을 representation하려고 하다 보면 하나의 이미지에 완전히 fitting된 latent vector를 얻기보다는 좀 더 general한 특성을 가진 latent vector를 얻게 되는 것입니다. 그러다 보니 image manipulation을 하기에도 전체적으로 limited attribute에 대해서 진행될 가능성이 높아지게 됩니다.
따라서 대부분의 GAN Inversion Method들에서는 W+ Space를 사용하는 것이 일반적으로 좋다고 합니다. 실제로 앞서 언급했던 GAN Inversion의 주요 논문 중 하나인 pixel2style2pixel 일명 psp에는 다음과 같은 문장이 있습니다.
It has become common practice to encode real images into an extended latent space, W+, defined by the concatenation of 18 different 512-dimensional w vectors
당연하게도 본 논문 또한 W+ Space에서 모든 방식이 진행됩니다. 물론 GAN Inversion을 위한 latent space에 대해서는 P or P+ Space와 같은 추가적인 아이디어도 나왔지만, 본 논문에서는 사용하지 않기에 여기까지만 살펴보도록 하겠습니다.
추가적으로 이러한 W+ Space GAN Inversion or Editing을 위해서 GAN 자체를 W+ Space에서 학습시킬 필요는 없습니다. 애초에 StyleGAN의 아이디어 자체가 style regularizatoin과 같은 부분을 보더라도 different level에서 다른 style들을 반영해서 생성할 수 있게 학습이 되었기에 W+ space의 18x512의 latent vector들을 바로 사용하더라도 문제가 없습니다. 따라서 기존의 pretrained StyleGAN을 그냥 사용할 수 있습니다.
2.1.3. latent code manipulation
기존의 Image Editing을 위해서는 latent space 상에서 target attribute의 semantic direction을 찾은 후에 그러한 direction vector를 latent code에 더해줌으로써 edited code를 얻었습니다. 즉, latent code manipulation을 통해서 Image Editing을 했습니다. 하지만, 이러한 방식의 연구들은 모든 이미지들에 대해서 특정 attribute의 editing direction이 모두 같도록 했습니다. 즉, 하단의 이미지와 같이 smile attribute에 대한 direction을 찾게 되면 다른 이미지에 대해서도 동일한 direction으로 적용되게 했다는 것입니다.
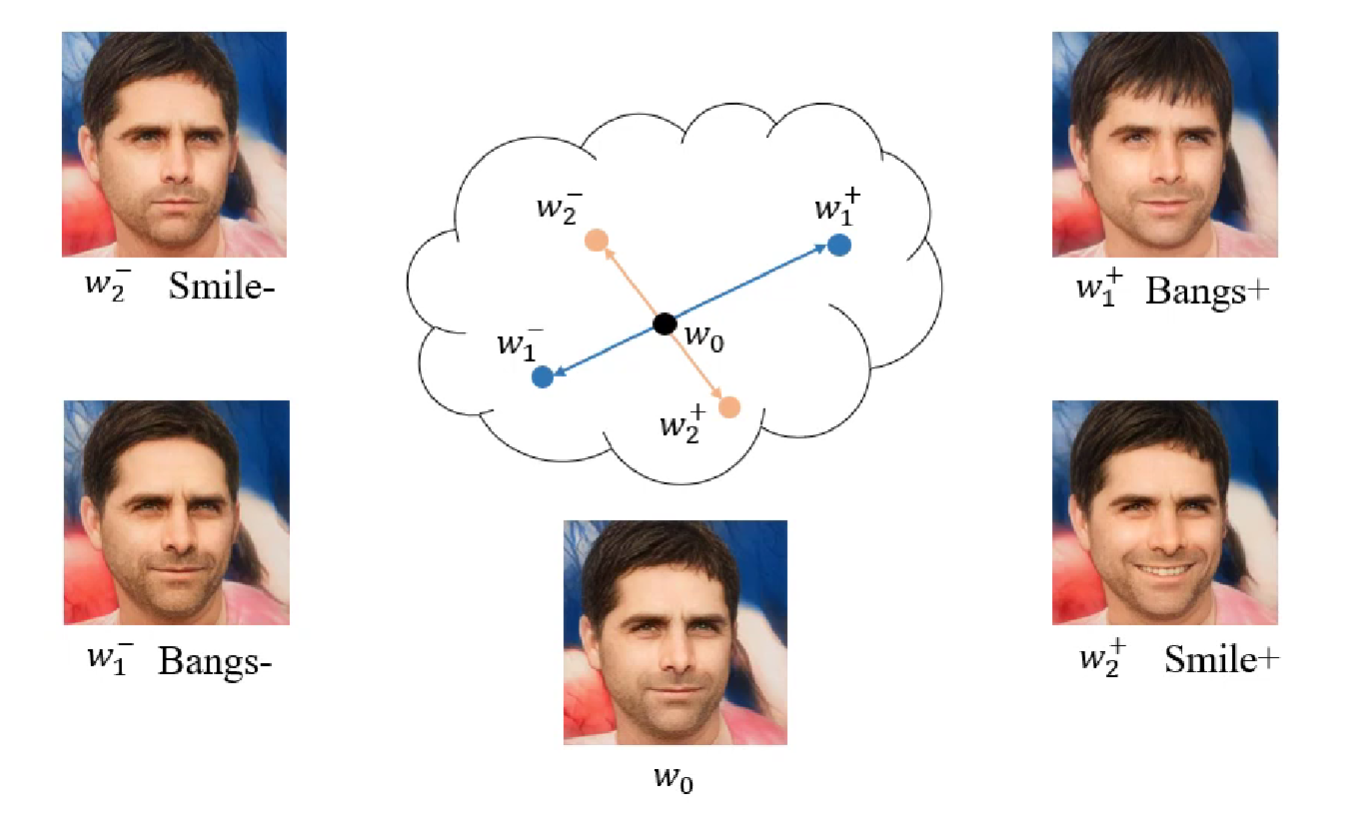
하지만 추후에 일부 논문들에서는 이미지별로 특정 attribute에 대한 editing을 위해서 adaptive edting direction을 사용하는 것이 더 좋다는 것을 주장했습니다. 본 논문에서는 이러한 최근 논문들의 주장을 이어받아, adaptive editing direction을 찾을 수 있도록 Image Editing Network를 설계하고 있습니다.
2.2. Attention
Vision의 영역에서도 Attention 및 Transformer 기반의 연구들이 많이 이루어지고 있습니다. 본 논문 또한 마찬가지인데요. 이러한 흐름 속에서 저는 Attention 메커니즘에 대해서 직관이 중요하다고 생각합니다. 직관을 얻는다는 목적 속에서 간단히 Attention에 대해서 살펴보고 넘어가도록 하겠습니다.
2.2.1. Attention Mechanism
Attention은 말 그대로 주의, 집중으로 세상의 다양한 정보들이 사람의 눈에 들어올 때 특정 정보에만 집중할 수 있는 것을 의미합니다. 하단의 이미지와 같이 시각 정보를 받아들이는 사람이 존재하고 다음과 같이 5개의 물체가 놓여있는 상황이라고 생각해봅시다. 사람의 시각 수용체는 본질적으로 빨간색과 같은 색상에 집중하게 되어있습니다. 하지만, 이 사람은 얼마 전에 책에 대한 생각을 했었습니다. 이런 상황을 고려할 때 사람은 다른 정보들은 필터링하고 중요한 책에 attention하게 됩니다.
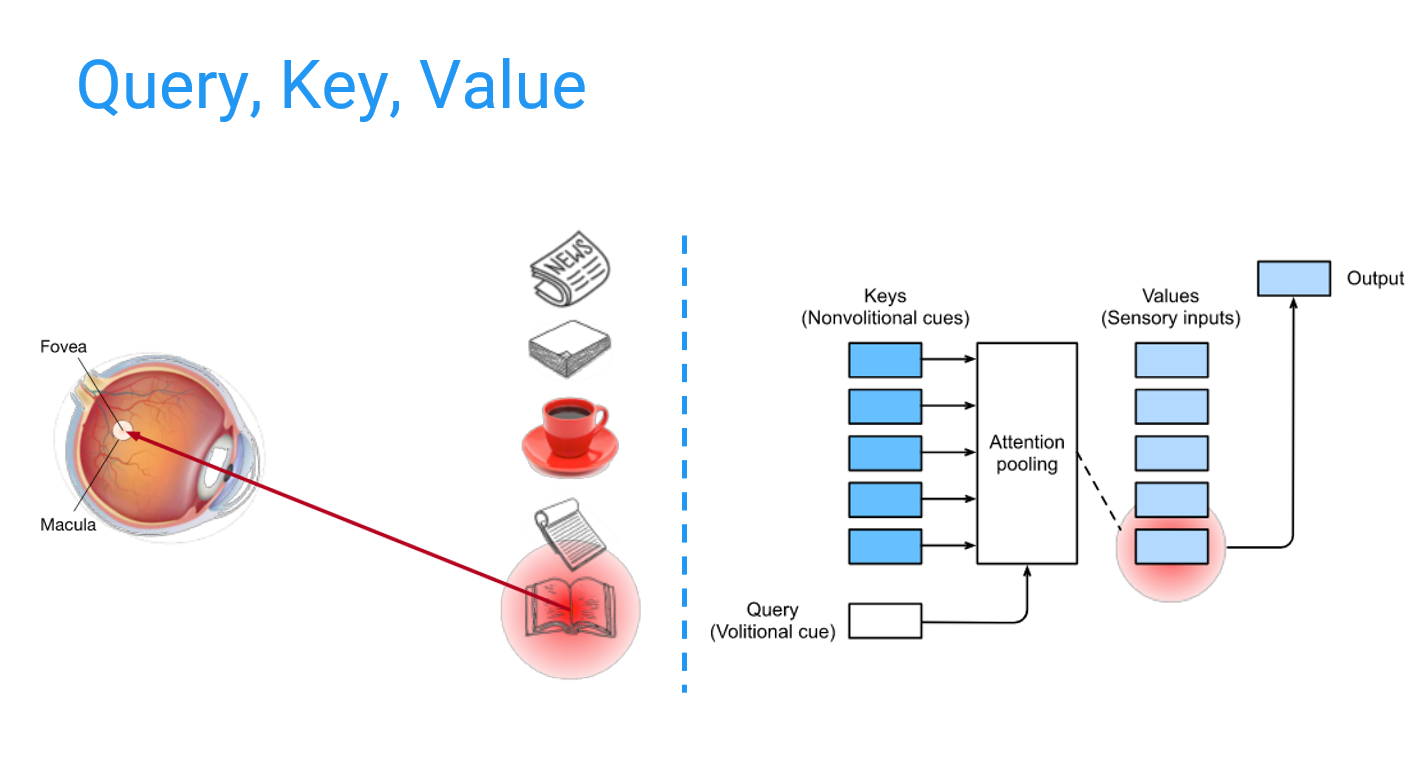
이러한 attention mechanism은 이전부터 존재하던 이론이었습니다. 하지만, Transformer논문에서 그 효용을 증명하면서 Game Changer가 되었습니다. 그렇다면 이러한 attention이 어떻게 이론적으로 정립되어 있고, 구현되는 것일까요?
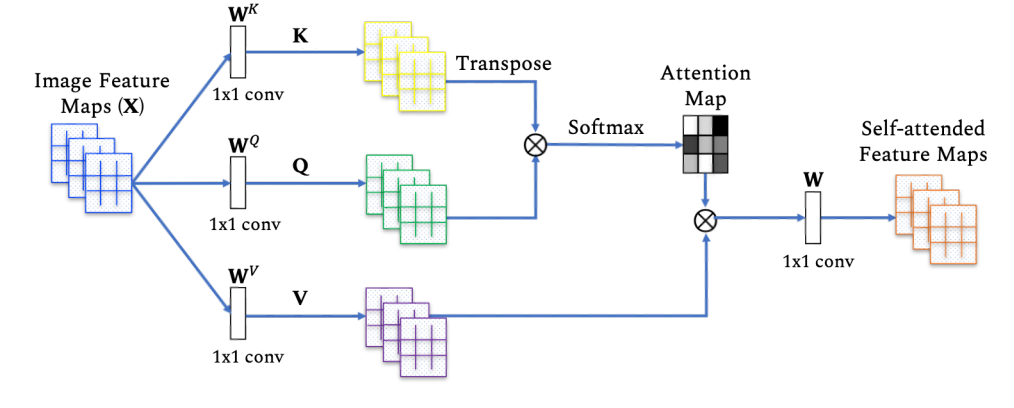
Attention Mechanism의 주요 component는 Query, Key, Value입니다. 논문의 표현을 빌리자면 다음과 같습니다. Attention in transformers is facilitated with the help of queries, keys, and values. 이때 3가지 component가 뉴럴 네트워크 학습에서 어떤 역할을 하는지를 이해하기에는 다양한 자료들이 존재하니 참고하시는 게 좋습니다. 여기서는 3가지 component가 하는 역할을 어떻게 직관적으로 이해해야 하는지에 집중하겠습니다. 각 component는 다음과 같이 이해할 수 있습니다.
Key : 앞서 언급했듯 사람은 세상의 다양한 의지에 상관없이 정보들을 얻습니다. (감각 같은 것 ) 상단의 이미지에서는 5가지 물체들에 대한 시각적인 정보를 받고 있는 상황입니다. Key는 이렇게 의도에 상관없이 얻게 되는 외부 정보들을 의미합니다.
Query : Key와는 대비되게 내재적으로 가지고 있는 정보를 의미합니다. 상단의 예시에서는 책에 대해 생각을 했었다는 정보 ( 책에 관심 있다는 정보 )가 될 수 있겠습니다.
Value : 항상 key와 pair한 정보로 key가 가지고 있는 정보 자체를 의미합니다. ( Query와 Key가 매칭될 때 Key자체가 아닌 Key에 해당하는 Value 정보가 Attention을 위한 information으로 사용되는 것입니다. )
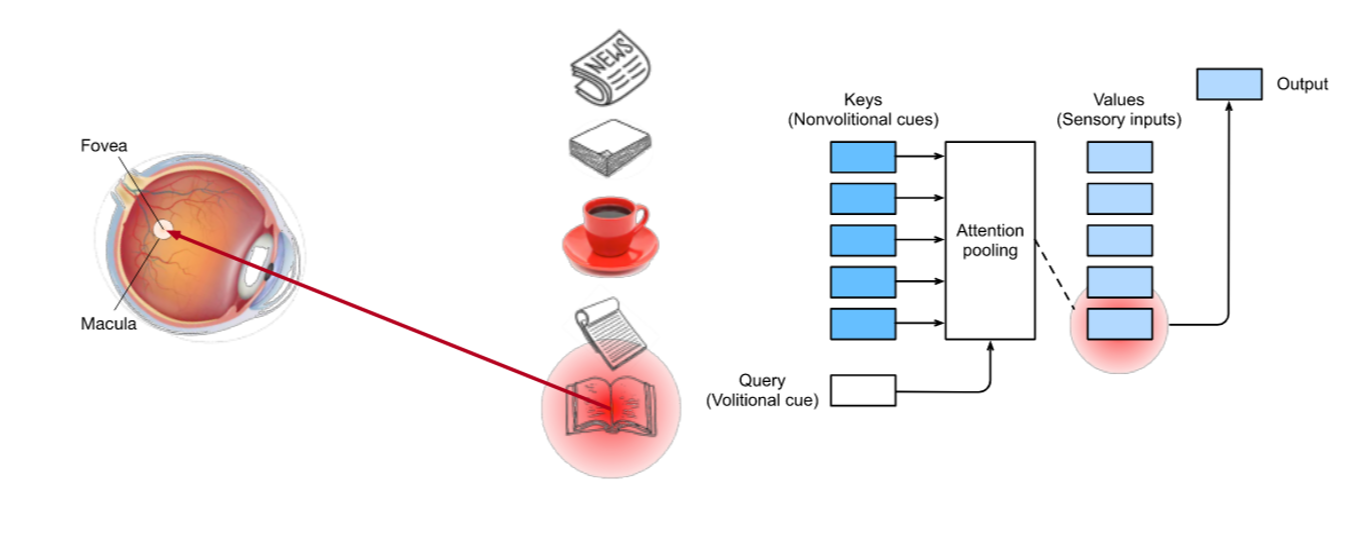
이렇게 3가지 component에 대한 간단한 이해를 바탕으로 상단의 예시를 다시 설명해보겠습니다.
사람은 세상의 5가지 물체 정보를 받습니다. ( Key ) 하지만, 사람은 기본적으로 붉은색과 같은 색상의 물체에 더 주목하게 됩니다.( high Value ) 즉, Key에 해당하는 Value가 높은 값을 가지고 있는 Key가 붉은색 찻잔인 것입니다. 이러한 붉은색 찻잔의 주목하게 되는 이유가 매치되는 value가 높은 값이기 때문입니다. 하지만, 그렇다고 해서 사람이 언제나 붉은색 찻잔에 집중하지는 않습니다. 그 이유는 사람이 책에 대해서 관심이 있었다는 등의 내재적인 정보가 있기 때문입니다. ( Query ) 따라서 이러한 Query, Key, Value가 적절히 고려되어 어디에 Attention할지가 결정됩니다. 크게 보자면 결국 Q란 내재한, 이미 가지고 있는 정보이며 K, V는 참고할 정보라고 이해할 수도 있을 것 같습니다.
이러한 Attention Mechanism을 뉴럴 네트워크로 확장해보면, 뉴럴 네트워크에서의 Attention Mechanism은 네트워크의 propagation과정에서 어떤 부분( 특정 이미지 패치 or 특정 단어 )에 집중할지에 대한 정보를 사용하여 더 좋은 학습을 하고자 하는 것입니다.
2.2.2. Self-Attention vs Cross-Attention
이러한 Attention방식 중 본 논문 이해를 위해 Self-attention과 Cross-attention을 비교해보도록 하겠습니다. 사실 개념 자체는 무척 간단합니다. self-attention이란Q, K, V가 모두 하나의 출처에서 나왔을 때 쓰는 말이고, cross-attention은 Q의 출처와 K, V의 출처가 다를 때 쓰는 말입니다.
따라서 본 논문에서는 실제로 latent vector들 간의 관계 정보를 파악하고자 할 때는 self-attention을 사용하고 ( 모두 출처가 latent vector ) latent vector에 feature map의 정보를(외부 정보) 반영하고자 할 때는 corss-attention을 사용합니다. ( query는 latent vector, key와 value는 feature map )
2.2.3. Multi-head Attention
추가적으로 Transformer를 다시 리마인드하면서 Multi-Head Attention을 사용하는 이유를 간단히 짚고 넘어가자면, Multi-Head Attention은 단순히 attnetion을 여러 개의 head 즉 서로 다른 파라미터들에 대해서 여러 번 실행하는 것입니다. 이를 통해서 하나의 query에 대해서 여러 key에 attention하게 만들 수 있고 이는 일종의 앙상블 역할을 통해 더 좋은 학습을 하도록 합니다. 해당 글의 말을 빌리자면 판타지에 나오는 머리가 여럿 달린 생물체가 다방면을 관찰하기 쉬운 것처럼!

3. Style Transformer
본 논문에서는 기존 연구들이 가진 아이디어를 활용해 GAN Inversion에서 less distortion을 가져가면서도 기존의 W+ space가 가진 문제점 개선을 위해 Transformer를 gradually latent vector updating에 사용하는 StyleTransformer를 제시했습니다. 전체 Network의 설계는 다음과 같습니다. 그럼 지금부터 찬찬히 살펴보도록 하겠습니다.
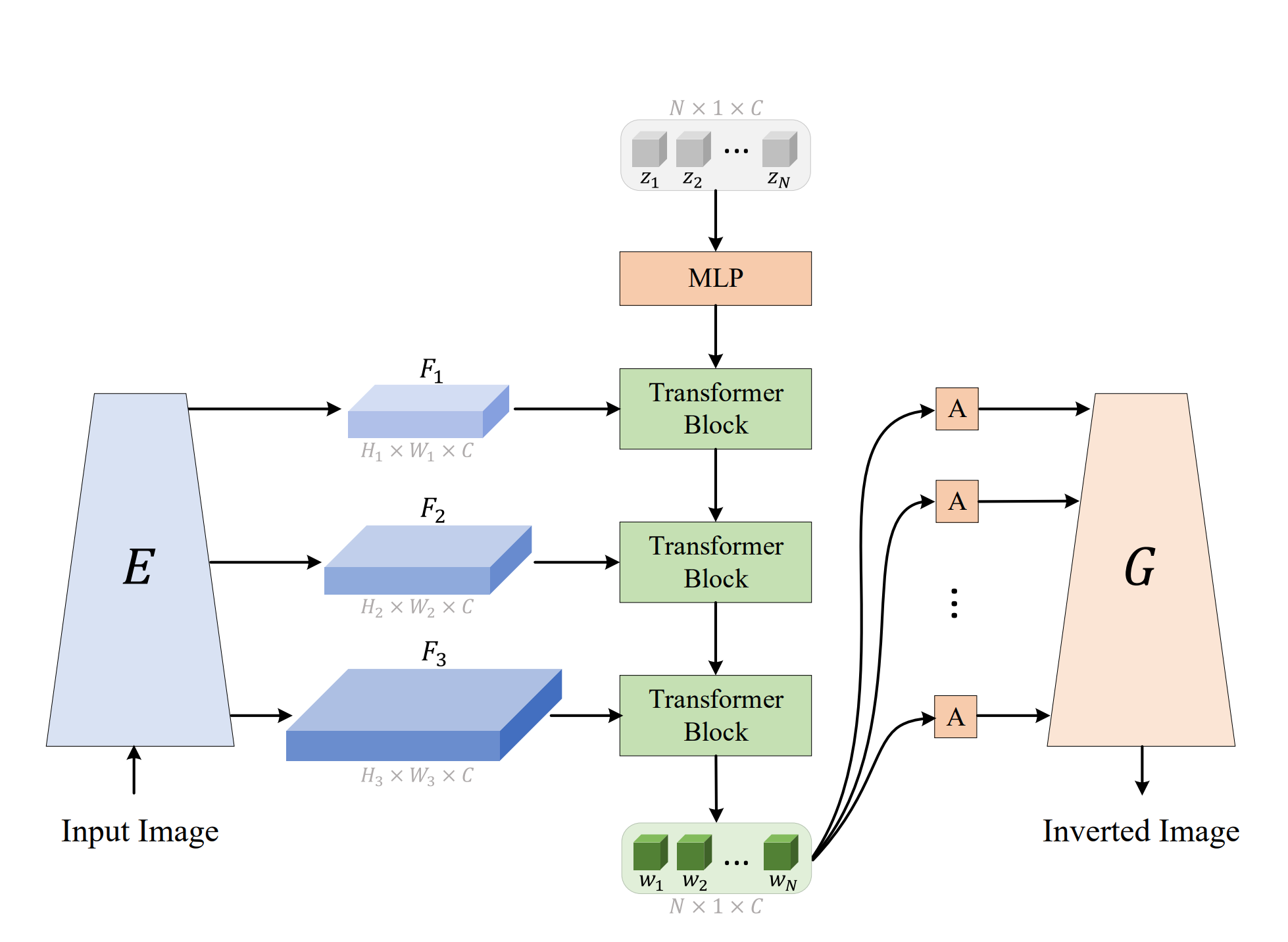
3.1. Multi-Scale Feature Map
먼저 전체 네트워크 구조 중 Encoder부분에서 multi-scale feature map을 만들어내고 있는 이유부터 살펴보겠습니다. 이러한 방식은 GAN Inversion에서 유명한 모델 중 하나인 psp(pixel2style2pixel)의 영향을 받은 것이다. 이를 위해 psp를 간단히 다시 살펴보면서 어떤 점에서 psp의 아이디어를 가져왔고, 왜 가져왔는지를 살펴보도록 하겠습니다. 간단히 설명하자면 psp에서 보인 multi-scale feature map을 통해 different resolutions에서의 이미지 디테일을 잡는 방식을 통해 less distortion한 reconstruction image를 만들어냈습니다. 본 논문에서는 이러한 psp의 feature pyramid encoder구조를 가져옴으로써 기존의 less distortion 특성을 유지하고자 했습니다.
3.1.1. Revisited psp ( pixel2style2pixel )
PSP는 앞서 말했던 GAN Inversion의 Encoder-based Method 중 하나입니다. Encoder Network를 이용해서 Input Image를 그냥 W+ space로 매핑을 진행합니다. 이때 PSP는 latent vector를 생성하는 encoder를 FPN에 기반한 네트워크로 구성합니다. 즉, 다양한 level에서의 feature map을 pyramid처럼 다양한 scale별로 나뉘고 이를 모두 사용한다는 것입니다.
또한, 추출된 피처 맵이 connection을 통해서 후반 부의 레이어에서도 사용하게 함으로써 더 풍부한 정보를 담게 해 디테일한 정보들까지 놓치지 않고 반영하게 하는 것입니다. 이때 각 scale의 feature map이 map2style block을 통해서 w+ space의 latent vector가 됩니다. 이렇게 feature pyramid encoder를 이용해서 inverting을 진행하게 될 경우 다른 scale, resolution에서의 이미지의 디테일한 정보까지 고려하기에 훨씬 적은 distortion을 가진 image가 reconstruction됩니다.
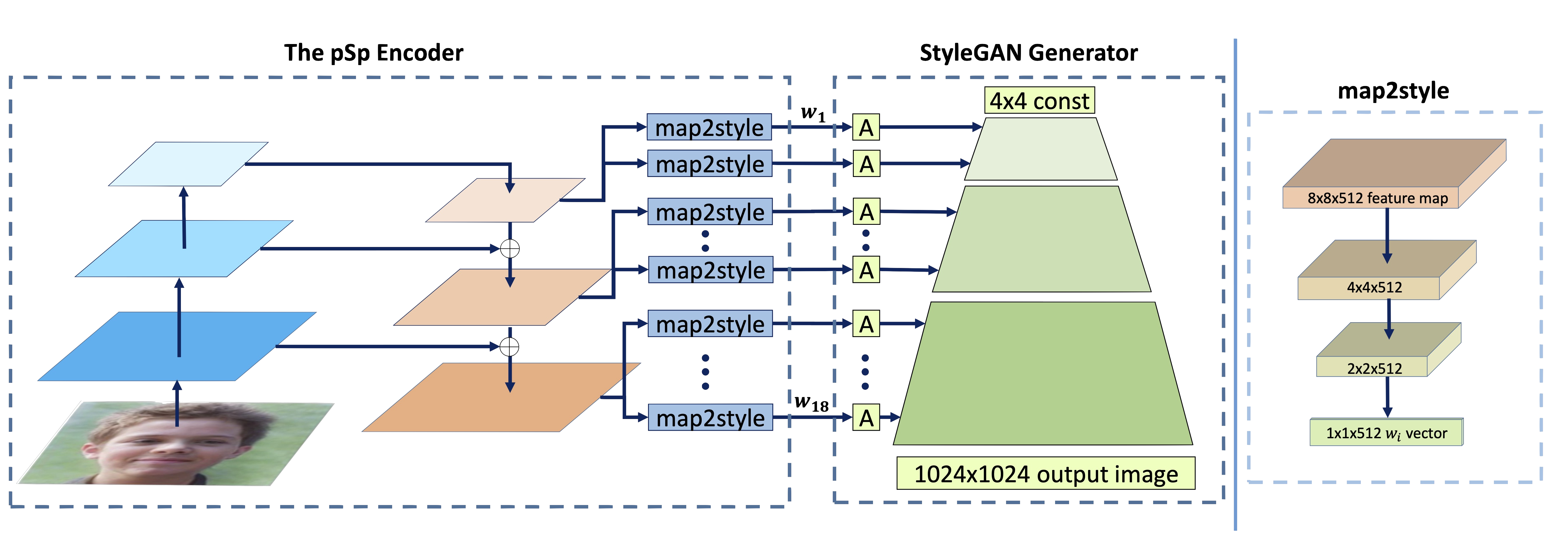
Style Transformer에서도 이러한 less distortion 특성을 가져오기 위해서 Encoder에서 multi-scale feature map을 뽑아 이용했습니다. 다만, Style Transformer에서는 이렇게 뽑힌 feature map을 map2style같은 CNN 네트워크를 거쳐서 style vector로 변환해 사용하는 것이 아니라 Transformer block에서 cross-attention의 key, value 등의 정보로 활용함으로써 더 나은 latent vector W+를 만들고 이를 Generator에서 사용하도록 했습니다.
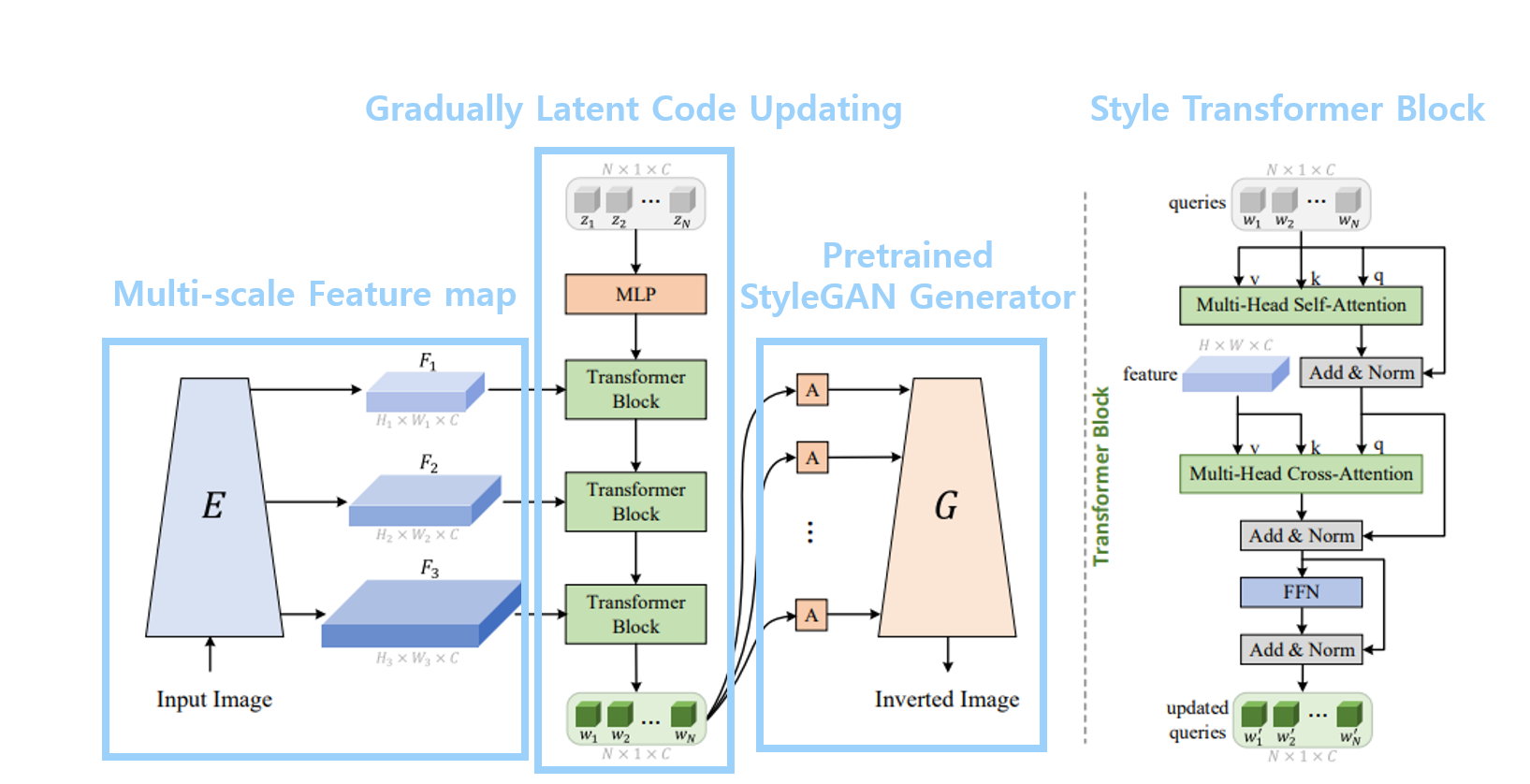
그렇다면 이때 이러한 multi-scale feature map를 반영해 less distortion을 가져가기 위해서 왜 이러한 Transformer Block을 사용했는지 그리고 어떻게 구성되어 있는지를 간단히 살펴보도록 합시다.
3.2. Style Transformer Block
결국 본 논문에서 하고 싶은 것은 좋은 latent code를 만들어내서 이러한 latent code를 다시 pretrained stylegan generator에 태워 좋은 이미지를 reconstruction하거나 editing하고 싶은 것입니다. 이를 위해서 본 논문에서는 Style Transformer Block을 사용해 query 즉 이미 가지고 있던 정보인 latent code를 점차 좋은 방향으로 업데이트해나감으로써 최종적으로 GAN Inversion에 적합한 final latent code를 얻고 이를 stylegan의 genrator에 넣어서 inverted image를 생성해냅니다. 주목할만한 점은 latent code 자체를 개선해나가는 방식의 구조로 설계되어있고, 이에 필요한 정보들을 활용해서 업데이트하기 위해서 transformer를 사용했다는 점입니다.
따라서 다시 한번 정리하자면 StyleGAN의 아이디어를 그대로 받아와 mlp를 통과한 w+ space의 latent vector로 initialization하는 것은 당연하고 이를 적절한 level의 feature map정보를 이용해서 더 좋은 latent vector로 업데이트해나가는 attention과정을 거치는 것입니다.
Style Transformer block에서 Transformer를 사용하는 이유는 크게 두 가지로 나눌 수 있습니다.
1. W+ space 에 대한 regularizaiton이 필요
2. multi-scale feature map을 잘 활용해 latent code를 update하기 위한 구조 설계
이때 본 논문에서 제시한 Style Transformer block에서 사용하고 있는 attention 방식도 2가지로 바로 self-attention과 cross-attention입니다. 각 이유에 따라서 어떤 목적으로 특정 attention을 사용하고 있고, 왜 이러한 attention을 통해서 목적에 부합한 결과를 얻을 수 있는지를 살펴보도록 하겠습니다.
3.2.1. W+ Space Regularization ( Self-Attention )
앞서도 언급했듯 GAN Inversion Method에서는 주로 W+ Space를 사용하는 것이 유용하기에 본 논문에서도 W+ Space의 latent vector를 사용하고 있습니다. 즉, stylegan2에 들어가는 각 latent vector들은 모두 본질적으로 다른 스케일에서의 디테일들을 묘사하고 있습니다. 결국 Input Image는 Inverting Step을 거쳐 W+ latent vector(18x512)가 나오게 되고 이것이 StyleGAN의 Generator의 서로 다른 stage에 들어가서 이미지가 생성됩니다. 하지만, 이러한 W+ space의 latent code는 각각 generator의 다른 stage로 들어가기에 학습 시에 충분한 regularization이 되지 않는다면 퀄리티가 떨어질 수 있습니다. StyleGAN에서 mixing regularization을 통해서 성능을 높였던 것과 같은 맥락이고, 18개가 모두 다른 latent code가 되면서 이런 문제가 발생할 수 있었다는 것입니다.
따라서 본 논문에서는 Self-attention을 통해서 Regularization의 효과를 줍니다. 현재의 문제 상황은 W+ space를 사용해 generator에 들어가는 다른 stage에서의 latent code들이 너무 개별적이어서 어느 정도 regularization이 필요한 상황입니다. 따라서 다른 scale에서의 latent code들 간의 link, 어느 정도의 관계 정보를 이용하게 된다면 이러한 regularization이 가능해지게 됩니다. 그렇다면 Self-Attention은 어떻게 이러한 역할을 해주는 것일까요?
Why Self-Attention?
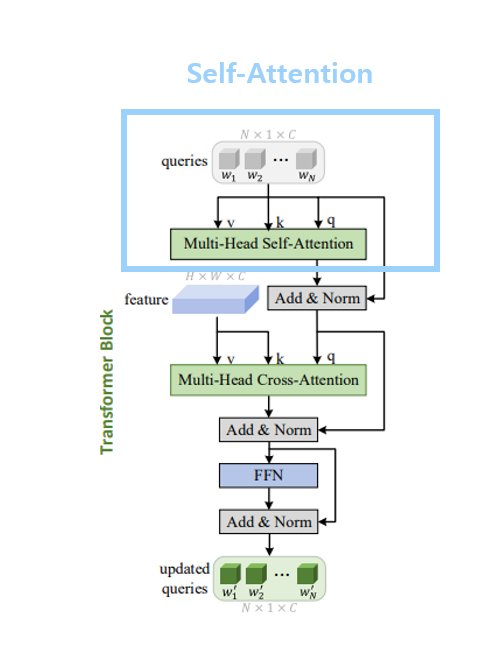
우선 앞서도 살펴봤듯 Self-attention은 Q, K, V가 모두 같은 출처에서 나왔을 때 쓰는 말입니다. 지금처럼 query token으로 받게 되는 latent vector들은 추후 stylegan generator에서 각각의 stage에 들어가 각각의 scale에서의 정보 디테일을 전달하게 됩니다. 이러한 N개의 latent vector( N은 stylegan generator에서 필요한 w+ latent vector의 개수 만약 1024x1024를 만들어낸다면 N=18 )는 각각 다른 레벨에서의 정보 디테일 역할을 하지만 결국 이러한 style vector( affined latent vector )들의 조합으로 최종적인 이미지가 생성됩니다. 따라서 어느 정도 서로 다른 level에서의 latent vector 간의 관계가 존재할 것이고 이러한 정보가 잘 반영되어야 latent code가 각 different level의 정보로 사용되면서도 서로 간의 관계를 고려해 너무 이상하지 않은(어느 정도 regularization 된) 이미지를 생성할 수 있을 것입니다. 그렇기 때문에 특정 이미지를 생성하기 위해서는 모든 query token들 간의 관계 즉, 다른 stage에서의 spatial 정보간의 realation에도 주목할 필요가 있습니다. 이를 위해서 self-attention을 사용하고 있습니다. 당연하게도 quey token들간의 relation 정보를 attention value로 뽑다 보니, Q, K, V의 출처는 모두 같은 query token 혹은 updated( or not ) latent vector일 것입니다. 따라서 Self-Attention을 사용함으로써 다른 stage에서의 latent code들 간의 관계를 학습함으로써 regularization의 효과를 얻을 수 있는 것입니다.
3.2.2. Multi-scale feature map Utilization
앞서 Multi-scale feature map에 대해 살펴봤습니다. 하지만, 지금까지의 네트워크 상에서는 어디에서도 이 정보를 사용하고 있지 않습니다. 또한, latent code를 점진적으로 업데이트해나가는 네트워크 설계 속에서 이러한 multi-scale feature map이라는 input image로부터 나온 정보를 어떻게 반영할지 미지수입니다. 이러한 역할을 위해서 cross-attention을 사용합니다. 즉, multi-scale feature map 정보를 사용해야 less distortion한 결과를 만들 수 있는데 아직 사용하지 않고 있습니다.
이러한 feature map정보는 cross-attention을 통해 반영됩니다. 앞서 self-attention을 통해 얻은 정보와 image에서 추출된 feature map을 바탕으로 이미지에 더 특화된 inverted latent vector를 얻기 위해 추가적인 attention을 진행한다는 것입니다. 그렇게 함으로써 quey token으로 사용되는 이전의 self-attention의 결과인 attention value에 different resolutions의 feature map들로부터의 정보를 반영함으로써 더 개선된 latent vector로 업데이트해나가는 것입니다. 즉 query는 self attention으로부터 오고 key, value는 feature map으로부터 온다는 것이다. 이렇게 feature map 정보 반영을 해주기 위해서 cross attention을 사용한 것입니다.
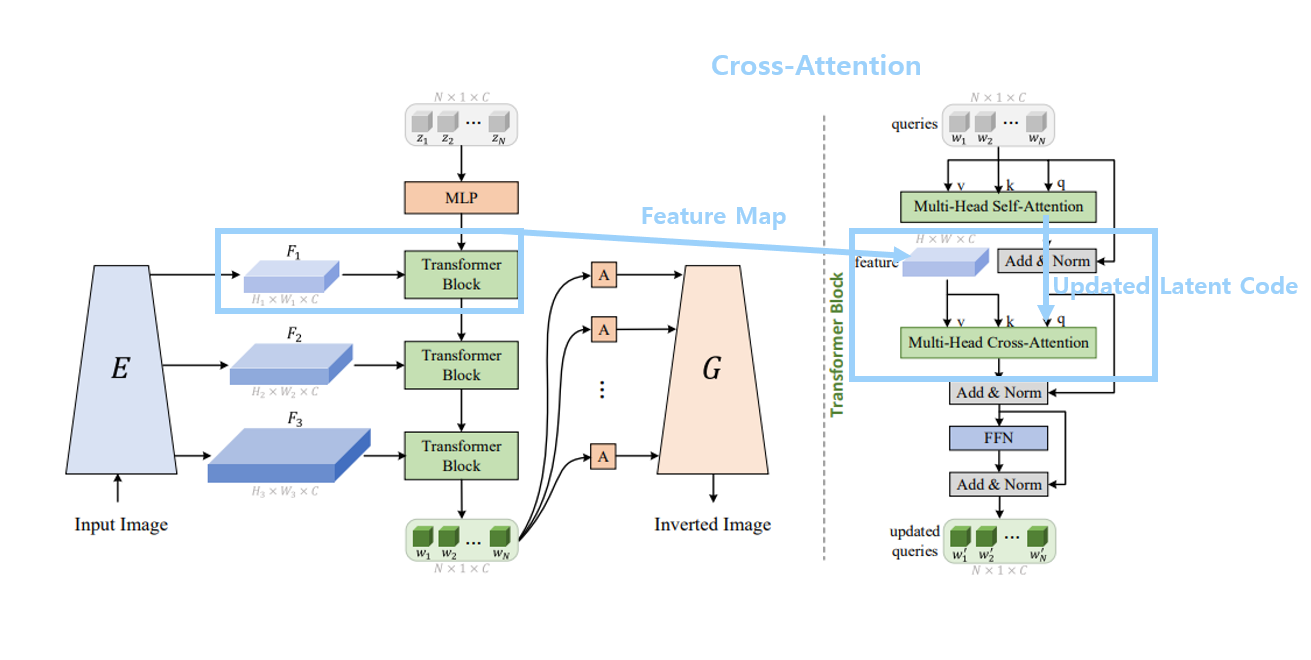
따라서 query token과 image feature가 interact를 하면서 점진적으로 다른 resolution에서의 이미지 디테일 정보를 고려해나가면서 query를 업데이트해나갑니다. ( all low resolution to high resolution ) 이렇게 gradually multiple cross attention을 통해 앞서 self-attention을 통해 학습한 query안에 있는 general한 content는 점차 input image에 맞게 refine되어나가 충분히 디테일한 정보들을 학습해 좋은 inverting이 가능해지는 것입니다.
결국 다양한 정보들 즉, different level에서 생성 이미지의 디테일에 영향을 주는 latent vector들 간의 관계 정보와 multi-scale feature map 등을 모두 고려해서 좋은 inversion을 하도록 디자인된 것입니다.
we propose novel multi-stage style transformer in W+ space to invert image accurately. The transformer includes the self- and cross-attention modules, in which the style queries gradually get updated from the multi-scale image features.
3.3. Objective Function
언제나 학습을 위해서는 Objective Function이 필요합니다. 본 논문에서는 앞서 언급했던 psp의 objective function을 그대로 사용하고 있습니다. psp의 objecttive function은 다음과 같습니다. 다만, 본격적으로 설명하기에 앞서 몇 가지 notation을 확인하고 각각의 term을 하나씩 설명하도록 하겠습니다.
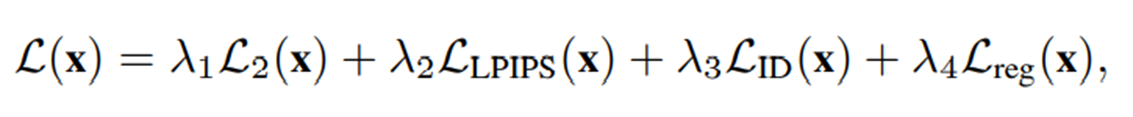
먼저 psp의 objective function을 기준으로 설명하기 위해서 psp operation이 담은 의미부터 살펴보도록 하겠습니다. GAN Inversion임을 고려할 때 x : Input Image / E : Encoder Network / G : Pretrained StyleGAN Generator임을 알면 Inverted Image를 생성하는 operation이라는 것은 이해가 되지만, w-라는 부분이 붙은 이유는 잘 납득이 가지 않을 수 있습니다. 이는 average stryle vector w- 를 사용해서 잔차인 residual을 학습하도록 해 좋은 initalization에서 시작해서 얼마나 거리가 있는지를 계산하는 것이 즉, 인코더에서 평균으로부터의 차이를 찾게 하는 것이 학습하기가 훨씬 쉽기에 다음과 같은 구조로 psp network는 residual한 학습을 진행하는 것입니다.
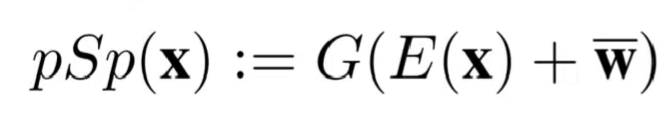
그 외에도 각 notation들은 다음과 같은 바를 의미합니다.
x : Input Image
E : Encoder Network
G : Pretrained StyleGAN Generator
F : Feature Extraction Network
R : ArcFace Network

psp의 objective function을 이해하는 데에 있어 나동빈 님께서 정리해주신 내용이 아주 좋습니다.
- 1은 말 그대로 reconstruction된 이미지와 원래 input 이미지 간의 차이가 적도록 하는 reconstruction loss
- 2는 perceptual loss처럼, GAN Inversion에서도 이미지 자체 공간에서 차이를 좁히는 reconstruction loss보다 Feature 공간에서의 차이를 measure하는 것이 효과적이라고 했기에 이를 measure하는 LPIPS입니다.
- 3은 arcface라는 사전 학습된 face identity에 대한 네트워크를 사용한 것으로 input image와 reconstruction image의 face identity가 얼마나 유사한지를 cosine similiarity로 measure해서 loss로 사용하는 것입니다.
- 4는 stylegan에서의 truncation trick과 유사하게 평균 latent vector에 가깝도록 하는 것이 어느 정도 fidelity를 보장해줄 수 있는 방법이기에 이렇게 regularization term을 걸어주게 됩니다.
앞서 말했듯 Style Transformer에서는 이러한 Objective Function을 동일하게 사용합니다.
결국 Style Transformer는 앞서 살펴봤던 이유로 style transformer block을 사용해 학습하고 다음과 같은 loss로 measure함으로써 좋은 GAN Inversion Method를 제시합니다. 하지만, 본 논문의 기여는 gan inversion에만 있지 않고, image editing에도 있습니다. 지금부터 Image Editing을 위해 본 논문에서 제시한 새로운 네트워크와 내용을 살펴보도록 하겠습니다.
4. Image Editing in Style Transformer
앞서 언급했듯 Image Editing은 GAN Inversion의 quality를 평가하기 위해서나 Practical한 영역에서의 수요로 인해 중요합니다. 2.3. latent code manipulation에서도 살펴봤듯 manipulation을 위해서 offset을 더해줌으로써 image editing을 진행했었습니다.( w e = w s + ∆w )본 논문에서도 이러한 큰 틀은 가져옵니다. 하지만, offset에 대해서 다른 관점으로 접근함으로써 이전에는 잘 되지 않았던 reference-based editing을 진행합니다. 또한 기존의 연구들은 binary attribute에 대해서 latent space 상의 linear seperation을 가정하는데, (StyleGAN에서도 확인 가능합니다.) 이러한 가정 하에서는 서로 다른 이미지들에 대해서도 같은 attribute에 대해서는 같은 direction을 가지게 됩니다. 본 논문에서는 이러한 identical dirction은 editing quality와 diversity를 낮추기에 적절하지 못하다고 주장하며 image에 adaptive한 editing direction을 적용하는 방법을 제시합니다.
물론 Image Editing은 크게 2가지 영역으로 나눌 수 있습니다. Label based와 Reference based로. 특정 특성을 label로 정의해두고 label에 따라 attribute를 바꾸는 것과 reference의 특성에 기반해서 바꾸는 것입니다. 이전의 연구들을 살펴보면 Label based 방식이 많았기에, 본 논문에서도 Label-based 많은 초점을 두지는 않고 있습니다. 따라서 본 리뷰에서는 Refernce based방식을 살펴보도록 하겠습니다. ( 솔직히 제 생각을 말씀드리자면 논문을 붙이기 위해서 빈 내용을 채우는 것처럼 Label-based 방식도 넣은 것 같습니다. ㅎㅎ; )
물론 방법에 상관없이 앞서 살펴봤던 inverting 방법은 negligible distortion을 가지기에 W+ space의 latent vector들에 대해서 K개의 binary attribute를 classifying할 수 있는 latent classifier C를 학습시킬 수 있습니다. 이러한 C는 사전 학습된 상태로 준비되게 됩니다. ( 기존의 다른 연구들처럼 attribute에 대한 classifier를 사용한다고 생각해도 좋습니다. 다만, Inversion방법론이 less distortion을 가지기에 더 좋다 정도로 이해하면 될 것 같습니다. )
4.1. Reference-based Editing
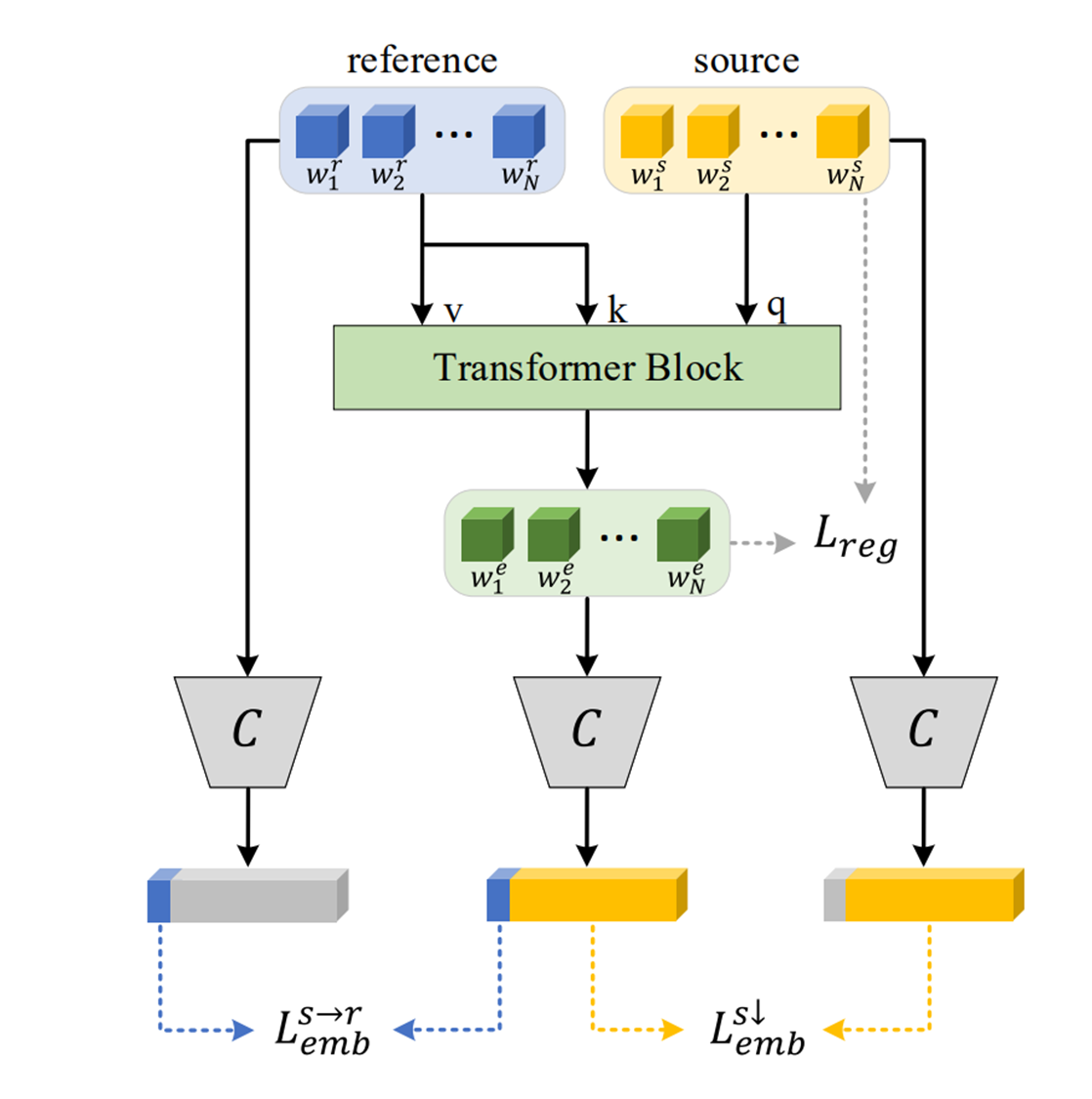
4.1.1. Offset ∆w ( Edit Transformer : T )
Reference based editing의 경우 reference로부터 우리는 정확한 editing vector 즉, offset ∆w을 결정하기를 원합니다. 본 논문에서는 다시 transformer를 활용해서 새로운 관점으로 offset ∆w를 더하게 됩니다.
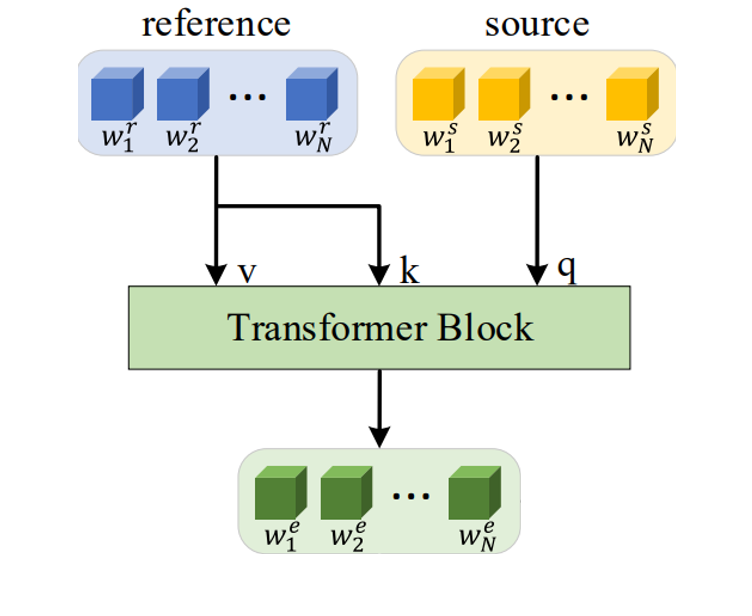
본 연구에서는 기존의 연구들처럼 global direction을 찾은 후에 offset으로 더해주는 것이 아닌 source inverted latent code를 query로 reference inverted latent code는 key, value로 사용하는 cross attention을 수행해서 각 source , reference image를 고려한 즉 이미지에 adaptive하게 학습을 할 수 있습니다. 물론 attribute를 구분해야 하므로 앞서 사전 학습시켰던 latent classifier supervision하에서 attention module이 학습되는 것은 마찬가지입니다. 이렇게 transformer를 사용함으로써 adaptive direction을 offset으로 사용하는 것과 같은 효과를 얻어 diverse result를 얻으면서도 이미지의 퀄리티를 유지할 수 있게 됩니다.
따라서 본 논문에서는 Editing을 위해서 모듈을 새롭게 디자인했습니다. 앞서 살펴봤던 Style Transformer는 Inverting step이었다면 본 논문에서는 inverting step 후에 editing을 위한 모듈을 학습시키기 위해서 추가 학습을 진행해야 합니다. 이 모듈은 T라고 하고 cross attention으로 되어 있습니다
좀 더 디테일하게 어떻게 학습되는지를 살펴보자면 T 모듈에서는 앞서 말했던 cross-attention을 통해서 source latent code에서 특정 attribute가 reference 의 특정 attribute로 바뀐 edited latent code w^e를 얻게 됩니다. 즉, T 모듈을 통해서 offset인 ∆w를 학습해 editied latent code를 구할 수 있다는 것입니다.
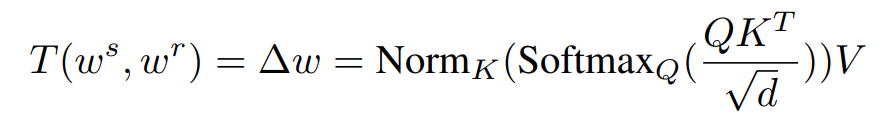
4.1.2. Training Edit Transformer ( with loss measure )
source(w^s), reference(w^r), editied(w^e) 3가지 latent code를 모두 사전 학습된 latent classifier에 태워 k개의 binary attribute에 대한 각각의 logit값들을 얻습니다.
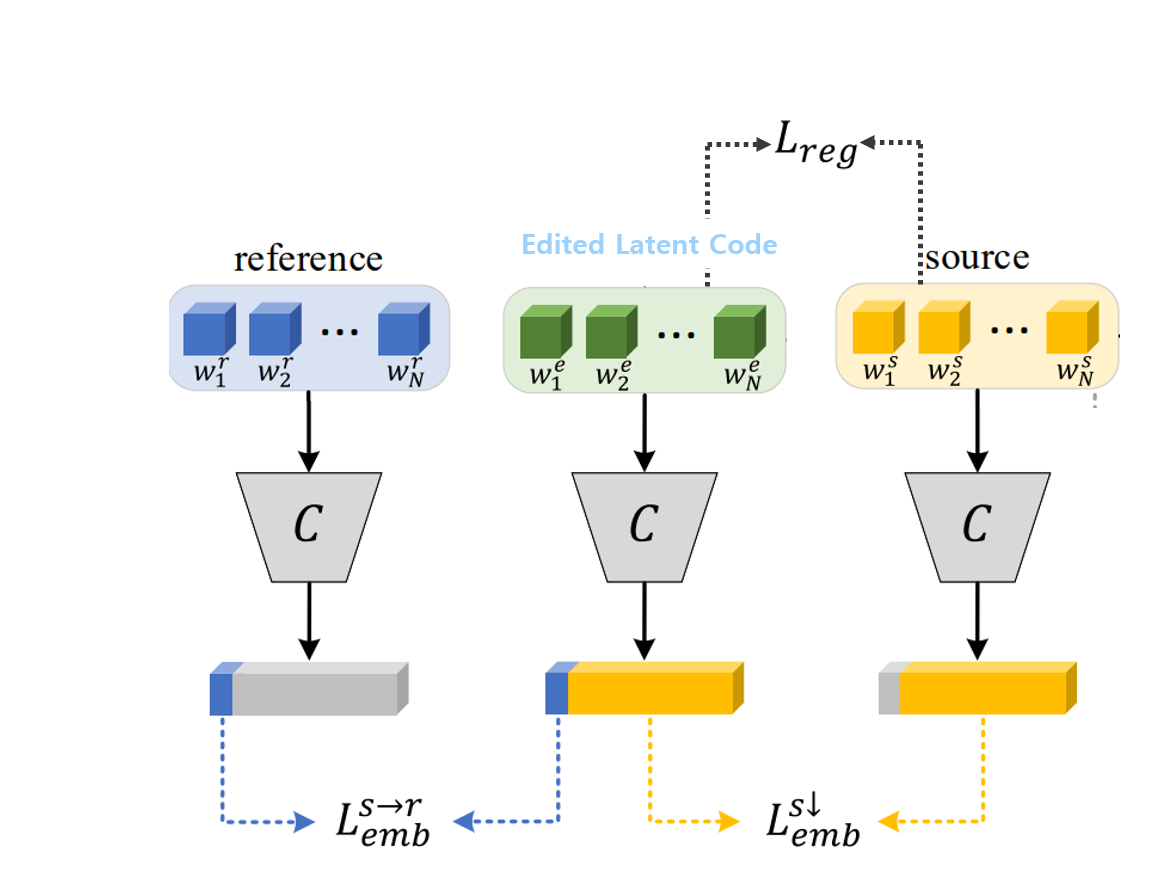
이때 특정 attribute는 editing되어 reference 것을 따르게 하기 위해서 다음과 같이 k라는 특정 attribute에 대해서 Classifier C가 edited latent code와 reference latent code가 각각 뱉은 logit의 L2-norm을 loss를 measure하게 되고, ( k번째 attribute가 reference의 style로 editing될 수 있도록 )
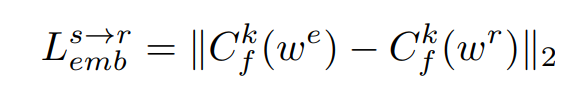
4.1.2. Training Edit Transformer ( with loss measure )
source(w^s), reference(w^r), editied(w^e) 3가지 latent code를 모두 사전 학습된 latent classifier에 태워 k개의 binary attribute에 대한 각각의 logit값들을 얻습니다.
나머지 attribute는 editing되지 않고 source의 identity를 유지하게 하기 위해서 다음과 같이 k라는 특정 attribute를 제외한 모든 attribute들에 대해서 Classifier C가 edited latent code와 source latent code가 각각 뱉은 logit의 L2-norm을 loss를 measure하게 됩니다. ( k 이외의 모든 attribute가 source의 style을 유지할 수 있도록 )
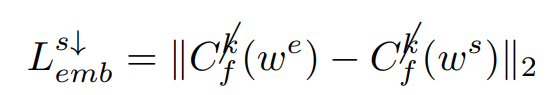
또한, 특정 attribute를 변형시키면서 source에서 너무 많은 변화가 일어나는 것을 지양하기 위해서 추가적으로 regularization term을 통해서 source latent code와 너무 차이 나지 않도록 합니다.
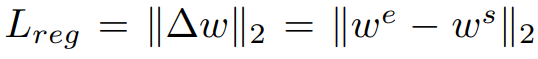
이렇게 T 모듈 혹은 Edit Transformer를 학습하게 됩니다. 이때 학습에 사용될 data는 latent code입니다. 따라서 기존의 StyleGAN 학습에 사용했던 latent code들을 batch별로 source와 reference로 나눠서 학습을 진행하고 있습니다. ( 학습과정에서 굳이 inverted latent code를 사용할 필요는 없으므로 ) 따라서 이 Editing Step과 Inverting Step은 완전히 독립적으로 학습된다는 것을 주의해야합니다.
이러한 학습 구조를 가짐으로써 adaptive direction을 offset으로 사용하는 것과 같은 효과를 얻어 diverse result를 얻으면서도 이미지의 퀄리티를 유지할 수 있게 되면서 latent code를 이용하는 구조이기에 Reference의 latent code를 학습에 사용함으로써 Reference-based Image Editing도 손쉽게 가능하도록 했습니다.
5. Results
실제로 Inversion에 대한 결과를 확인해보면, 다음과 같이 qualitative한 관점에서나 quantitive한 관점에서나 모두 상당히 좋은 성능을 보여주고 있는 것을 확인할 수 있습니다.
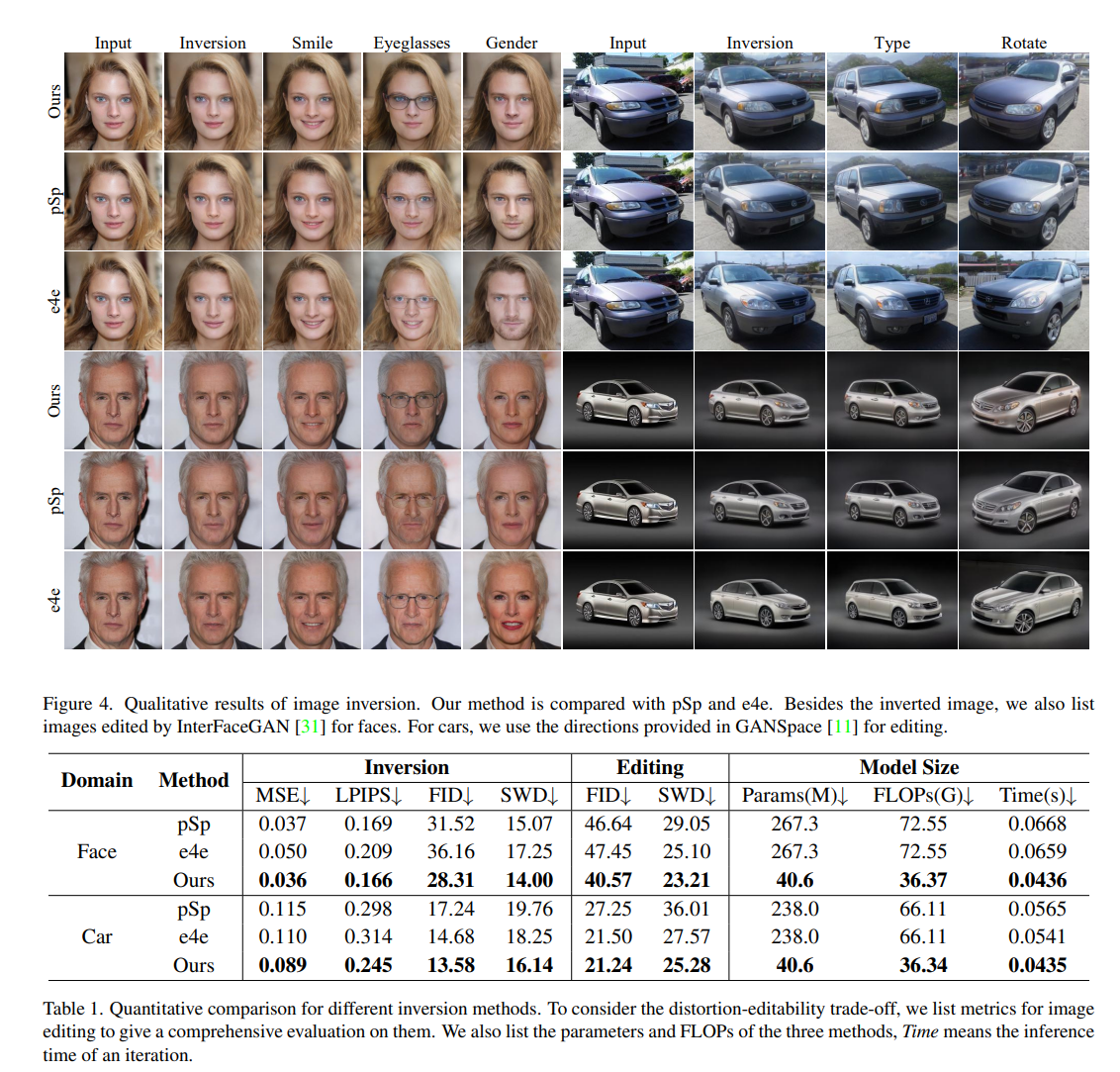
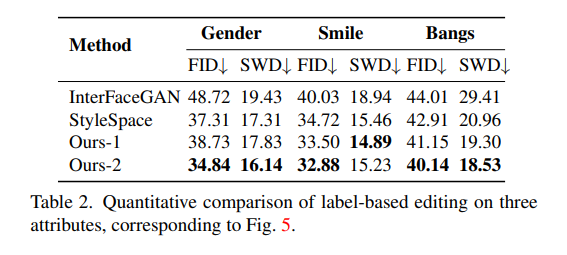
또한, Editing의 quality를 판단하기 위해서도 qualitative한 관점에서나 quantitive한 관점에서 모두 확인해본 결과 마찬가지로 좋은 결과를 보여주고 있다는 것을 확인할 수 있다.

References
- CVPR 저자 발표 영상 : https://www.youtube.com/watch?v=5VL2yYCgByQ
- 나동빈님 pSp 설명 영상 : https://www.youtube.com/watch?v=x5oYjBqq-zw
- https://milkclouds.work/attention-is-all-you-need-nips-2017/#:~:text=%EC%B0%B8%EA%B3%A0%EB%A1%9C%20self%2Dattention%EC%9D%B4%EB%9E%80,%EA%B0%80%20%EB%8B%A4%EB%A5%BC%20%EB%95%8C%20%EC%93%B0%EB%8A%94%20%EB%A7%90%EC%9D%B4%EB%8B%A4
- GAN Inversion : Survey : https://arxiv.org/abs/2101.05278
- Attention Mechanisms in Computer Vision: A Survey : https://arxiv.org/abs/2111.07624


