안녕하세요 :) 이번에는 3d vision과 Graphics에서 새로운 지평을 가져다준 NeRF에 대해서 설명해보고자 합니다. 실제로 SLAM과 같이 결합되어 사용하는 등 다양한 방향으로 NeRF를 활용한 연구가 진행되고 있습니다. 이러한 NeRF를 명확히 이해하기 위해서는 다른 논문들에 비해 비교적 많은 Background가 필요하다고 생각합니다. 따라서 기존의 다른 논문 리뷰들과는 다르게 Background를 먼저 설명하고 NeRF에 대해서 설명하는 방향성으로 서술하도록 하겠습니다. 그럼 시작하겠습니다.
1. Background
Novel View Synthesis
처음 nerf가 등장했을 때 vanila nerf의 목적성은 view synthesis에 있었습니다. View Synthesis란 뭘까요? 이전부터 컴퓨터 비전과 그래픽스 커뮤니티에서는 특정 scene( ex -포크레인 object에 대한 scene)에 대해서 sparse 하게 여러 view에서 찍힌 이미지들만을 가지고 보지 못한 새로운 novel view에서의 이미지를 synthesis 하고 싶었습니다. (view는 말 그대로 특정 시선 방향에서 본 것을 의미합니다.) 이렇게 함으로써 continuous 한 현실을 discrete하게 인식하고 있는 컴퓨터에서도 continuous한 결과를 만들고 싶었던 것입니다. Nerf 계열 논문들이 결과를 continuous한 video로 보여주는 이유도 여기에 있습니다. ( 실제로 비디오가 완벽히 continuous한 것은 아니지만, 충분히 continuous 하게 표현할 수 있다는 점에서 어쨌든 맥락은 그렇습니다. )
- input : 동일 scene에 대한 sparse view에 대한 이미지.
- output : 내가 원하는 특정 view에 대한 이미지.
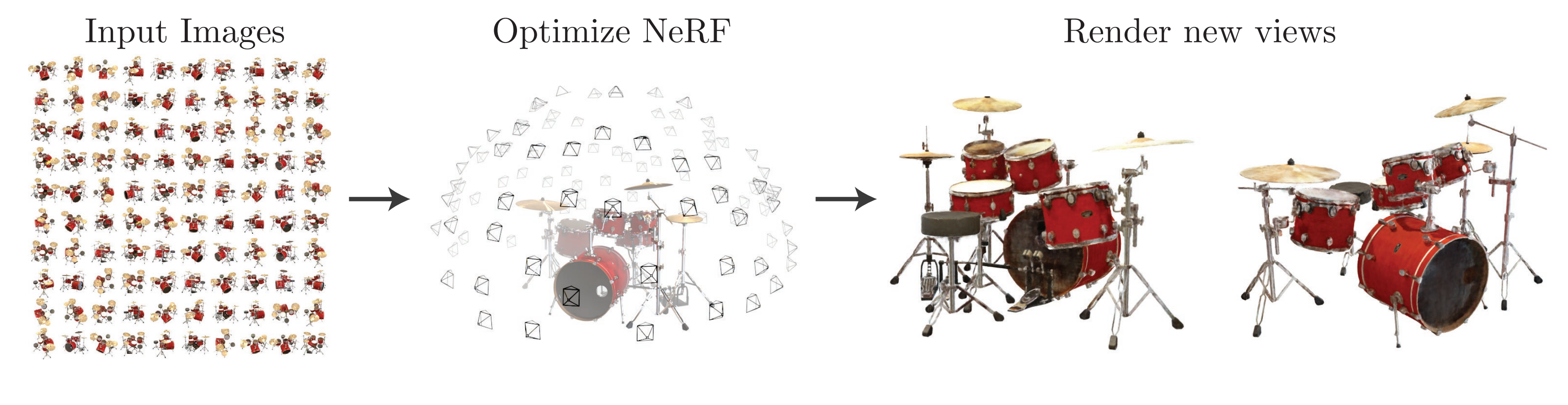

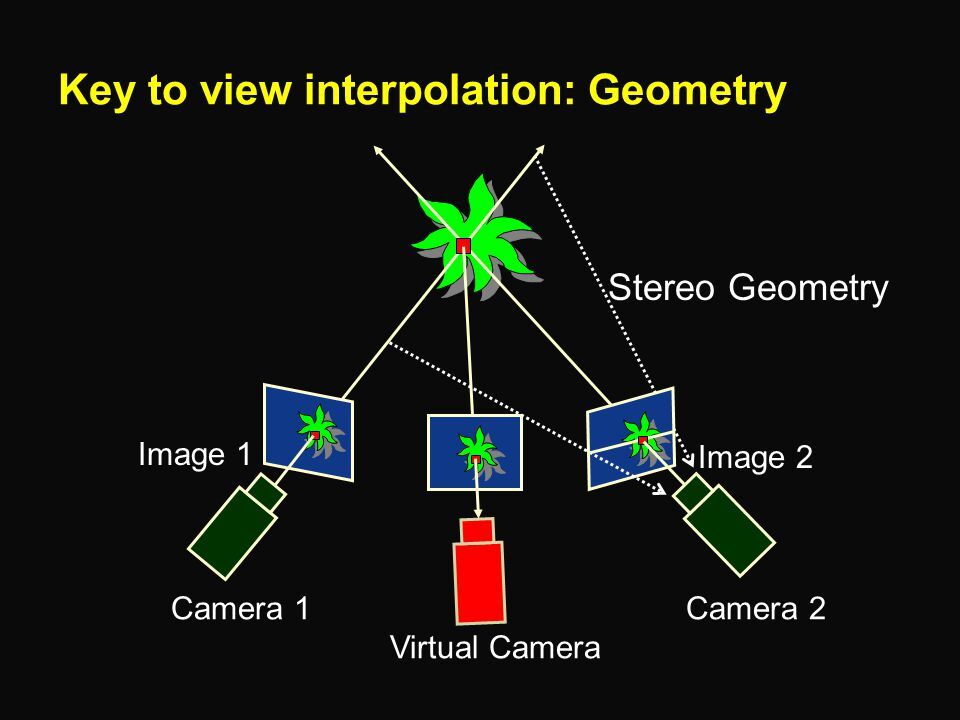
과거에는 유사한 의미로 view interpolation이 연구되었습니다. 다음과 같이 가지고 있는 view들에 대해서 interpolation을 통해 virtual ( nerf에서 novel ) view를 얻어내고자 했습니다. 하지만, 좋은 성능을 보이지는 못했고 그러던 와중 NeRF라는 압도적인 performance를 보여주는 연구가 등장하게 되었습니다.
결국 Nerf는 sparser view들만을 input으로 해서 novel view를 synthesis 하는 방법입니다. 이는 기존에 있던 분야였지만 Nerf에서는 이에 Neural Network를 사용해 continuous 5d scene representation의 파라미터를 rendering error를 minimize 하도록 optimizing 함으로써 새로운 방법론을 제시하며 탁월한 결과를 가져왔다는 점에서 의의가 있습니다. 즉, 다른 방법들보다 가장 우월한 방법이었기에 센세이션이 되었던 것입니다.
Radiance Field
what is radiance & radiance field?
Nerf는 사실 Neural Radiance Field를 뜻하는 말입니다. 그렇다면 Radiance는 뭐고 Radiance Field는 뭔지 알아야 할 것입니다. 이에 앞서 컴퓨터 그래픽스의 Phong Refelection Model을 잠깐 떠올려 봅시다. 물체 surface위의 특정 위치 p에 대해서 입력으로 빛이 들어올 때 여러 방향으로 튕겨나가는데 이때 물리적으로 복잡한 빛과 material의 interaction이 고려되어야 합니다. Phong을 이러한 물리적인 요소를 무시하고 모든 방향에 동일하게 반사되는 Ambient term, 특정 방향에 더 반짝 거리는 Diffuse term, 기본적인 칼라에 대한 Specular term이 있다고 가정합니다. ( 사실 이러한 Phong Reflection Model은 실시간 렌더링을 위해서 빠른 처리를 위해 만들어졌기 때문에 이러한 물리적이지 않은 모습을 가집니다. )

이는 실제 그래픽스에서 물체 관찰에 있어서 혹은 렌더링 등에 있어서 빛을 고려한다는 것입니다. 또한, Specular Term을 설계한 것을 보면 알 수 있듯이 다른 위치에서 같은 부분을 봤을 때 물리적으로 다른 색상으로 보여야 한다는 것입니다. 따라서 그래픽스에서 물리적이지 않은 모델링인 phong reflection도 modeling을 하게 되면 빛을 고려해 같은 부분이라도 다른 위치에서 바라봤을 때 다른 색상으로 보이게 됩니다. ( Graphics에서 BRDF )

사실 Radiance란 컴퓨터가 아닌 물리를 하는 사람들에게 빛을 의미합니다. 즉, 특정 지점을 특정 방향에서 관찰했을 때 나오는 color값입니다. 특정 물체를 볼 때 같은 부분을 정면에서 보는 것과 측면에서 봤을 때 다른 색상이라는 것입니다. 요지는 현실이든 모델링 된 곳이든 빛을 고려해 같은 물체의 같은 지점이라도 보는 위치에 따라서 다른 색상값을 가질 것 즉, 다른 색상으로 보일 것이라는 것입니다. 결국 특정 위치에서 특정 물체의 특정 지점을 바라봤을 때의 color값을 Radiance라고 하는 것입니다. 예를 들어 저러한 포크레인을 1번 view에서 봤을 때는 굉장히 샛노랗게 보이고, 2번 view에서 봤을 때는 덜 선명하고 연한 노란색으로 보일 거라는 것입니다. 이렇게 한 지점을 다양한 view에서 봤을 때 서로 다른 칼라값을 가지고, 이 color값을 radiance라고 하는 것입니다.

Radiance Field meaning in NeRF
Radiance Field란 특정 지점을 다양한 view에서 봤을 때 나오는 각 Radiance들을 통칭해서 부르는 것입니다. 즉 color들의 field인 것이죠. Nerf가 Neural Radiance Field인 이유는 바로 여기에 담겨 있습니다. 앞서도 잠깐 언급했듯 Nerf는 novel view synthesis를 하는 모델입니다. 이게 가능한 이유는 바로 물체들의 sparse 한 view들 가지고 물체가 있는 3d 공간 자체 즉 scene을 잘 이해할 수 있기 때문입니다. 즉 모델이 학습하는 representation이 바로 이 scene representation이라는 것입니다. 이때 이 scene representation을 mesh와 같은 explicit 한 정보가 아닌 해당 scene에 대해서 충분한 sparse view들로 학습함으로써 랜덤한 위치가 주어졌을 때 특정 view에서 그 위치의 색상 즉 radiance를 얻을 수 있는 잘 학습된 neural network가 있다면, 즉 이러한 radiance들로 이루어진 radiance field에 대한 정보를 neural net이 이해하고 있다면 그 scene에 대해서 충분히 이해하고 있다는 것입니다. 이렇게 radiance field를 neural net으로 인코딩하겠다는 것이고 이것이 곧 scene representation이라는 것입니다. 이렇게 scene자체를 neural net으로 이해하고 있다면 새로운 view도 synthesis 할 수 있다는 것이죠. ( 여기서는 완벽히 이해가 되지 않을 수 있습니다. 천천히 풀어서 아래에서 서술하겠습니다. )
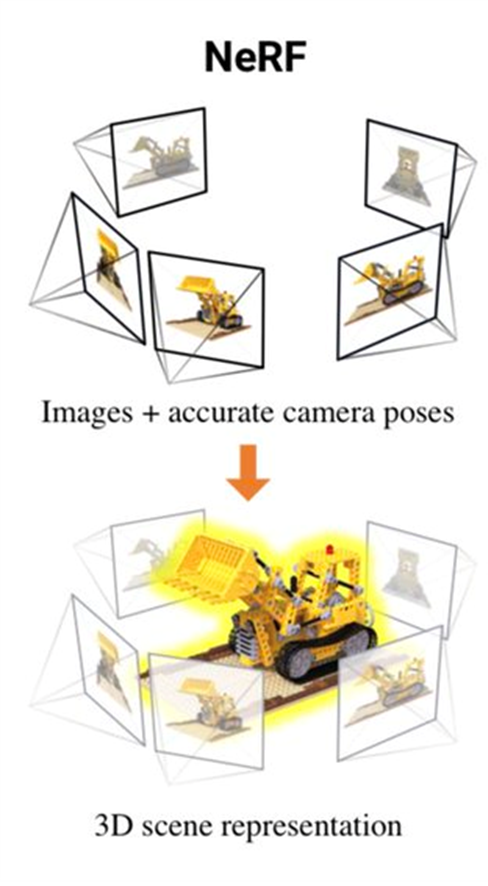

결국 NeRF는 Neural Radiance Field로 scene representation을 함으로써 새로운 view synthesis를 가능하게 하는 연구입니다. 이를 본격적으로 이해하기 위해서는 몇 가지 main comopnents들을 살펴봐야 합니다.
Ray
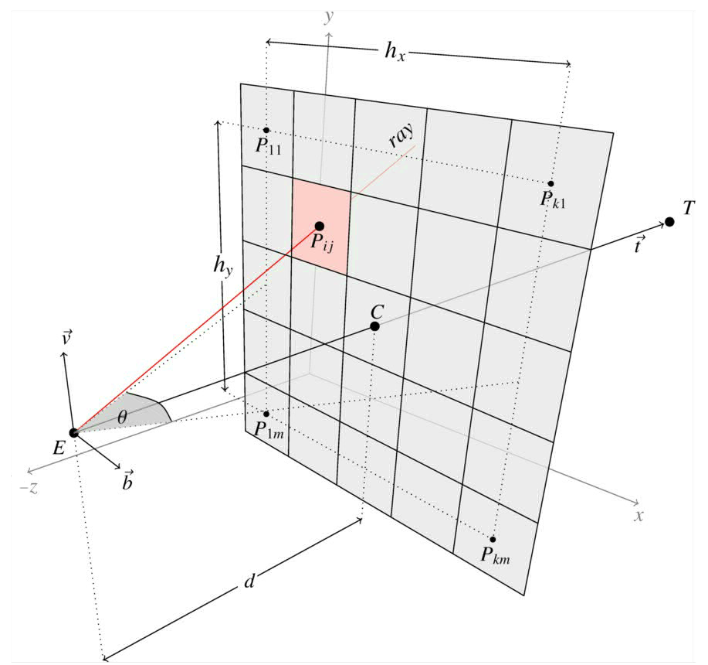
앞서도 빛에 대한 이야기를 했듯 사실 NeRF는 Light Field에 대한 연구들과 많은 것이 닮아 있습니다. 그런 맥락에서 3d computer graphics에서 photorealism을 위해 등장했던 Ray Tracing에서 사용하는 Ray의 개념을 가져옵니다. ( 사실은 그냥 volume rendering을 사용하기 위해서 ray의 개념을 가져온다고 생각해주시면 됩니다. ) Ray Tracing에 대해서 간단히 말하자면 앞서 Phong Reflection Model에서도 언급했듯 현실의 복잡한 빛과의 상호작용을 흉내내기 위해서 연속적으로 반사되는 빛을 고려하듯 ray들을 tracing 하는 방법입니다. 이러한 맥락에서 Ray란 이미지 평면 위의 픽셀 하나를 통과하는 3d 공간상의 직선입니다.
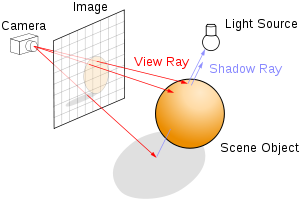
현실의 혹은 3d 공간 상의 물체를 바라본다고 할 때, camera 혹은 눈이 바라보는 지점을 eye point락 하고 3d 물체가 proejction 되는 viewing plane이 있을 것입니다. 즉, 3d volume이 존재한다고 할 때 이를 특정 view ( 사람이 서있는 것처럼 camera를 특정 pose에 두고 바라본다고 생각해봅시다.)에서 본다면 위와 같이 2d view image로 3d volume이 보이게 될 것입니다. 이때 이해해야 할 부분은 결국 3d volume이라는 것이 viewing plane에 2d image로 담긴다는 것입니다. 그래서 결국 픽셀들로 표현하고 나면 이 픽셀 하나하나를 통과하는 ray(광선)이 있다고 가정합니다. ( 당연하게도 이 광선은 3d model과 이어지겠죠) Ray의 핵심은 3d scene object에 대해서 이걸 viewing한 것을 결정할 때 이 ray들을 통해서 viewing plane의 image 픽셀 값들을 결정한다는 것입니다. ( Volume Rendering) 즉, 해당 ray가 통과하는 픽셀을 지나 3d 공간상의 위치들( 물체에 포함될 수도 있고, 아닐 수도 있는), 파티클들의 색상을 가중합하게 되면 ray가 통과하는 그 특정 픽셀의 값을 결정할 수 있다는 것입니다. 물론 이는 Computing Resource에 따라서 Pixel이 아닌 Grid단위로 이루어지기도 합니다. NeRF에서는 Volume Rendering을 사용하기 위해서 이러한 Ray의 개념을 가져옵니다.
Volume Rendering
Ray가 뭔지 이해했다면 본격적으로 NeRF의 Main Feature 중 하나인 Volume Rendering을 이해해봅시다. Volume Rendering은 3D Volume을 2d로 projection 할 때 이 2d view image를 결정하는 알고리즘화된 방법입니다. NeRF에서 Volume Rendering이 필요한 이유는 무엇일까요? 간단히 생각해보자면 3d scene에 대한 새로운 View를 synthesis할 때 즉 2d image를 만들 때 필요한 것입니다. 그런데, 이는 3d scene에 대한 정보를 가지고 있는 상황에서나 가능할 것입니다. 하지만, NeRF는 2d image들에서부터 시작합니다. 즉, NeRF의 세팅 자체가 scene에 대한 3d 정보가 전혀 없고 그걸 다양한 view에서 찍은 2d 정보들만 있다는 것입니다.
그렇다면 NeRF는 어떻게 Volume Rendering을 할 수 있는 걸까요? 핵심은 앞서 이야기했던 Scene Representation에 있습니다. 3d Scene을 잘 representation하고 있다면 이해하고 있다면 해당 Representation으로부터 volume rendering을 걸어 새로운 view synthesis를 할 수 있다는 것입니다. 이때 Volume Rendering을 걸기 위해서 필요한 factor들은 radiance와 density입니다. 그렇기에 Neural Radinace Field인 nerf가 학습되어 radiance field를 이해하고 있다면 바로 voluem rendering을 걸어 새로운 이미지를 합성할 수 있다는 것이다.
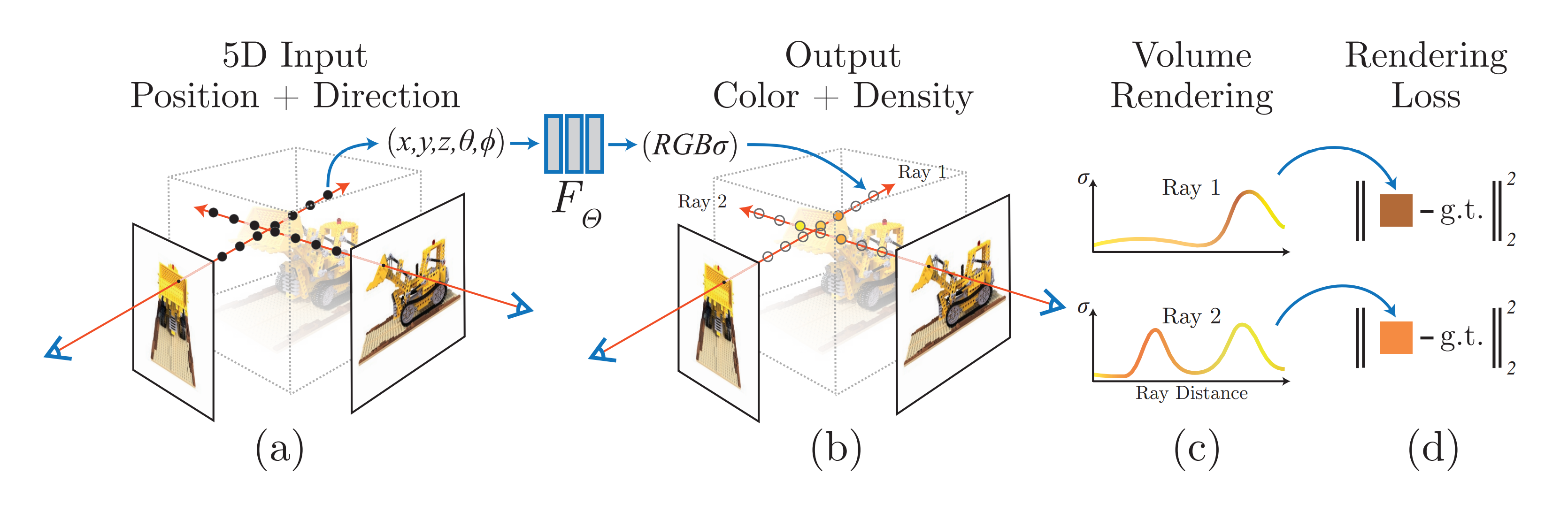
Vanila NeRF에서는 Volume Rendering으로 가장 근본적인 Volume Ray Casting방법을 사용하고 있습니다. NeRF에서는 그냥 ( Classical ) Volume Rendering으로 지칭하고 있으니 이를 그대로 사용하겠습니다. ( 굳이 구분을 둔 이유는 추후 NeRF의 후속 논문들에서 Volume Rendering에 새로운 기법을 적용한 연구들도 있기 때문입니다. ) Volume Rendering은 결국 3d volume 혹은 물체를 특정 view에서 봤을 때의 이미지 픽셀 값들을 결정하는 알고리즘입니다.
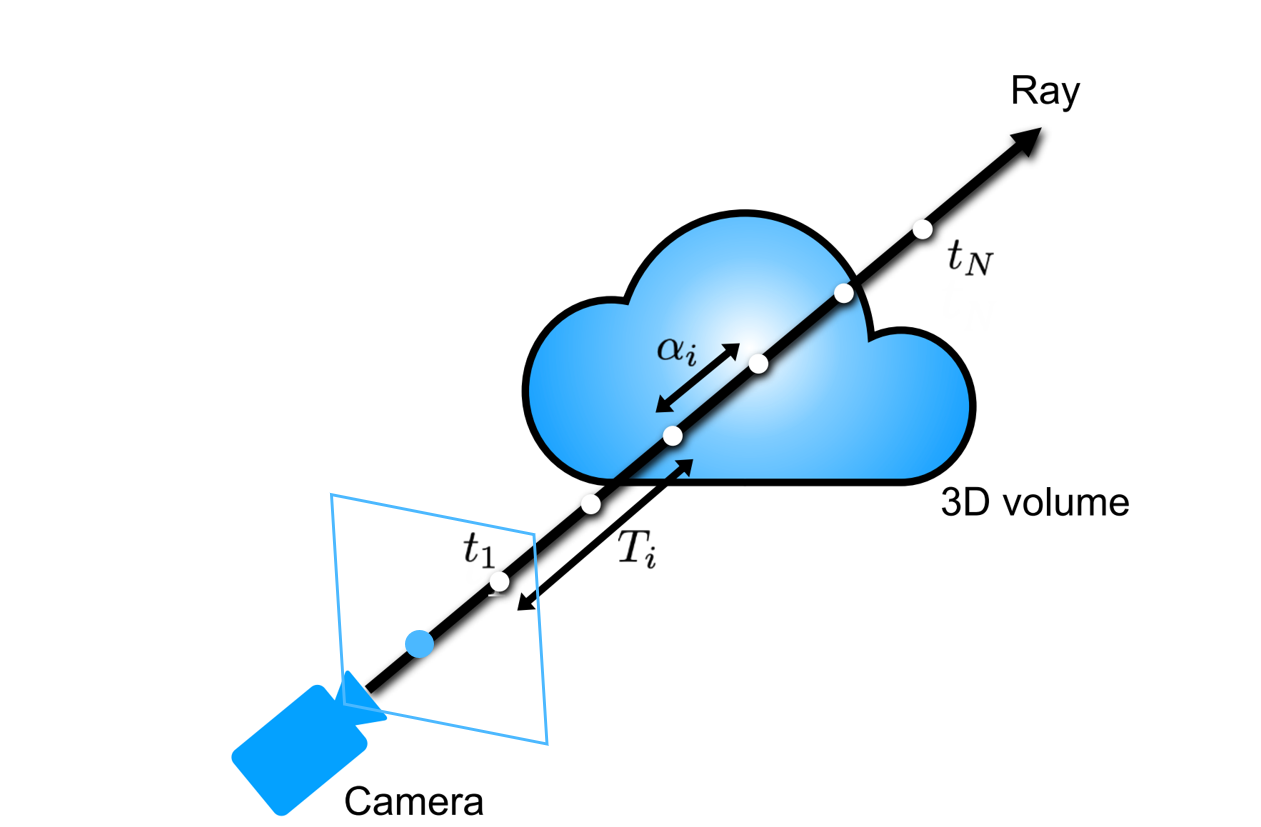
예를 들어, 저러한 구름과 같이 생긴 3d volume이 존재한다고 할 때 이를 특정 view ( 사람이 서있는 것처럼 camera를 특정 pose에 두고 바라본다고 생각해봅시다.)에서 본다면 다음과 같이 2d view image로 3d volume이 보이게 될 것입니다. 이때 이 2d view image의 특정 픽셀 값을 결정하기 위해서 Volume Rendering기법을 사용하게 되고 이 방법은 2d view의 각 픽셀마다 (그리드일 수도 있음 ) 하나의 Ray를 쏘고 이는 3d volume으로 투사되는데 이 Ray위의 각 point들의 color값들을 weighted average를 통해서 해당 ray가 통과한 픽셀 값을 결정하는 것입니다. 즉, ray를 쏘게 되면 다음과 같은 ray를 따라서 3d scene object가 2d view image의 픽셀 값에 담기는 것입니다. 해당 ray위에는 2d view의 해당 픽셀에 영향을 주는 3d scene의 모든 파티클이 존재하고, 이러한 파티클들의 색상의 가중합으로 해당 픽셀 값 즉 Radiance가 결정됩니다.
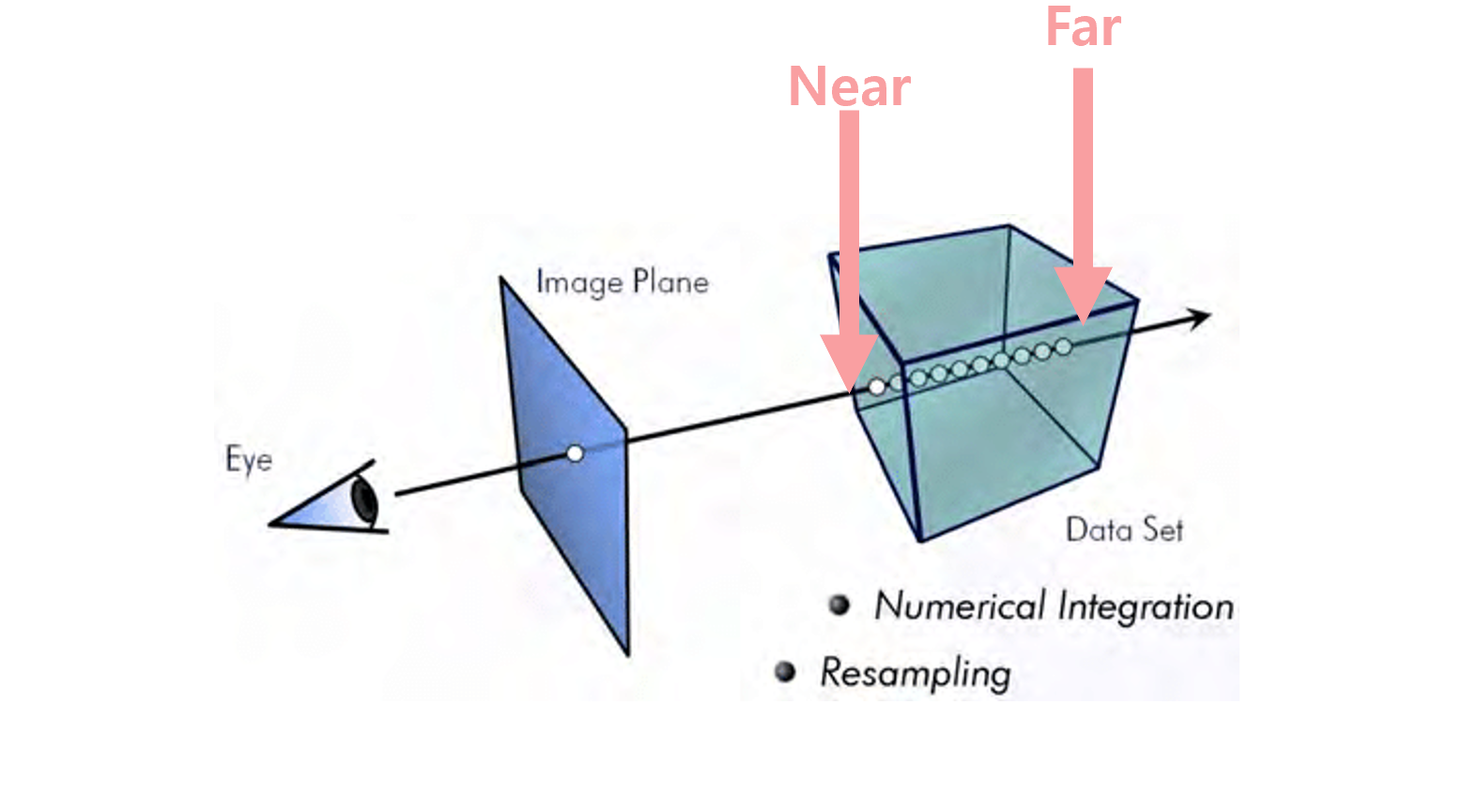
이러한 Classical Volume Rendering의 과정은 다음과 같습니다. Volume Rendering의 결과로 원하는 것은 C 즉, Radiance값입니다. 이러한 값은 Ray 상의 각 point들( marchong point - ray가 천천히 진전하면서 point들을 샘플링한다고 해서 이렇게 표현한다. 추후 ray자체를 샘플링하는 ray sampling과 헷갈리지 않도록 하자. )이 지니는 color값 c들을 가중합 해서 C를 구하게 됩니다.(이게 Volume Rendering입니다. ) 이때 우선적으로 Ray상의 point들 즉, 3d volume내에 있는 ray를 따라 나아가면서 ( marching ) point들을 샘플링합니다. 이러한 ray 상의 point들은 camera 위치 o를 기준으로 ray방향(d)으로 얼마큼(t) 갔는지이므로 r(t) = o + td와 같이 표현될 수 있습니다. 즉, ray의 방향 d로 t만큼 marching 전진한 것으로 r(t)는 ray 상의 새로운 위치 하나가 나온 것입니다.
참고로 이때 NeRF 구현체에서는 OpenGL의 Normalized device cooridante(NDC Space)로 모든 좌표계를 표현합니다. 즉, scene의 중심을 원점에 두고 이를 기준으로 x, y, z 축으로 [-1,1]만큼인 길이가 2인 bounding box( volume bounds)를 설정합니다. 따라서 카메라에서 시작한 perspective ray 상의 marching point들은 모두 NDC에서 표현됩니다. ( 즉 이 안으로 bound 하는 것입니다. ) 이렇기에 near과 far 또한 정의됩니다. ( 필자에게 편한 표현으로는 일종의 canonical view volume으로 표현한 것이라고 생각합니다. )
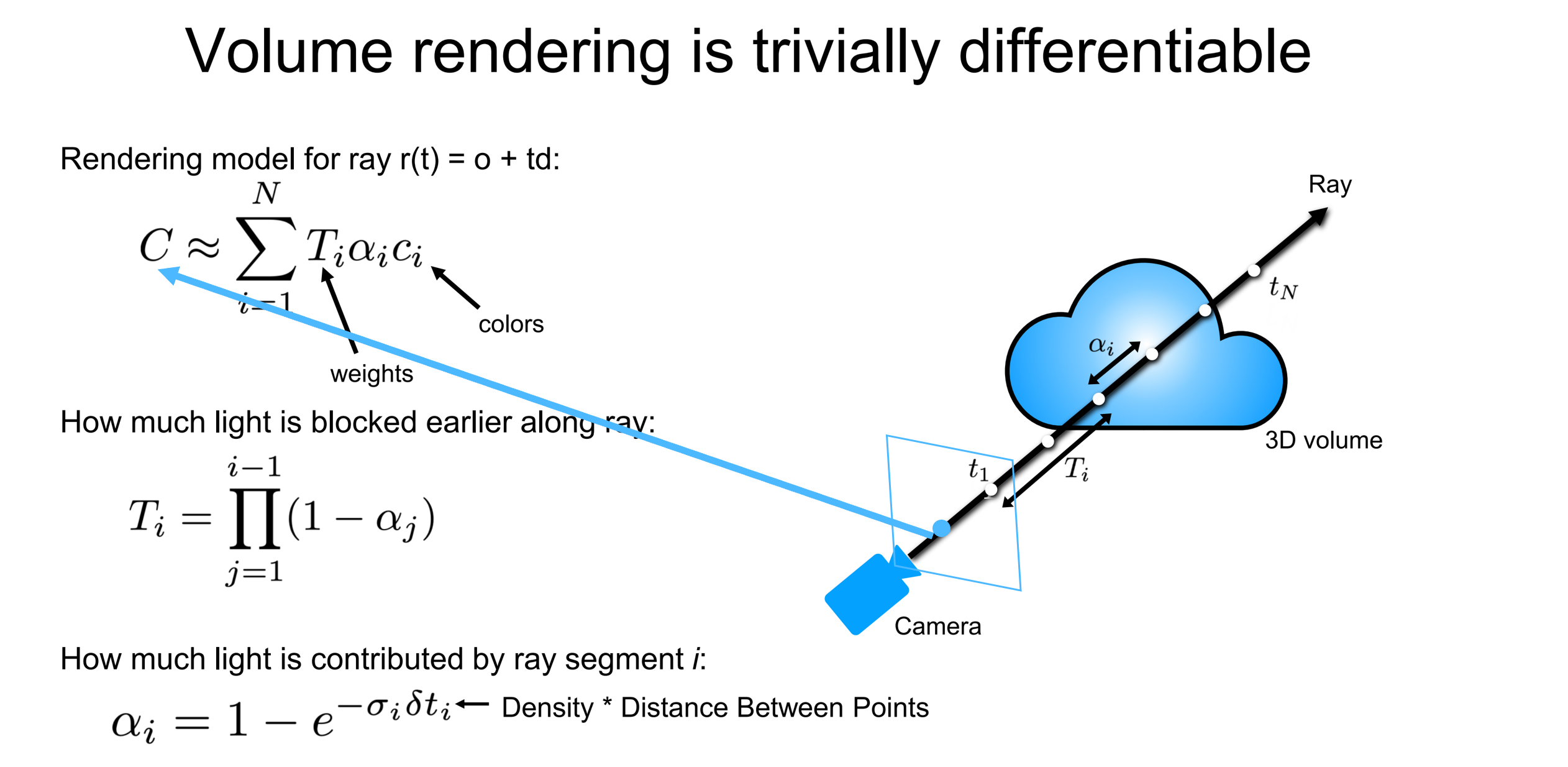
이러한 point들의 c값들을 가중합을 하게 될 때 Volume Rendering은 2가지 component를 더 고려합니다. 바로 T와 α입니다. T는 ray상의 near sampling point부터 far sampling point까지 ray를 따라서 accumulated transmittance를 의미합니다. 즉 near에서 far까지 ray 방향으로 누적된 투과도 즉, ray가 tn부터 t까지 가면서 어떤 파티클에도 부딪히지 않을 확률을 의미합니다. α의 경우 해당 샘플링 포인트 주변(바로 이전 포인트와 지금 포인트까지)에서 투명도를 의미합니다. 이러한 두 component들은 각각 위와 같이 정의됩니다.

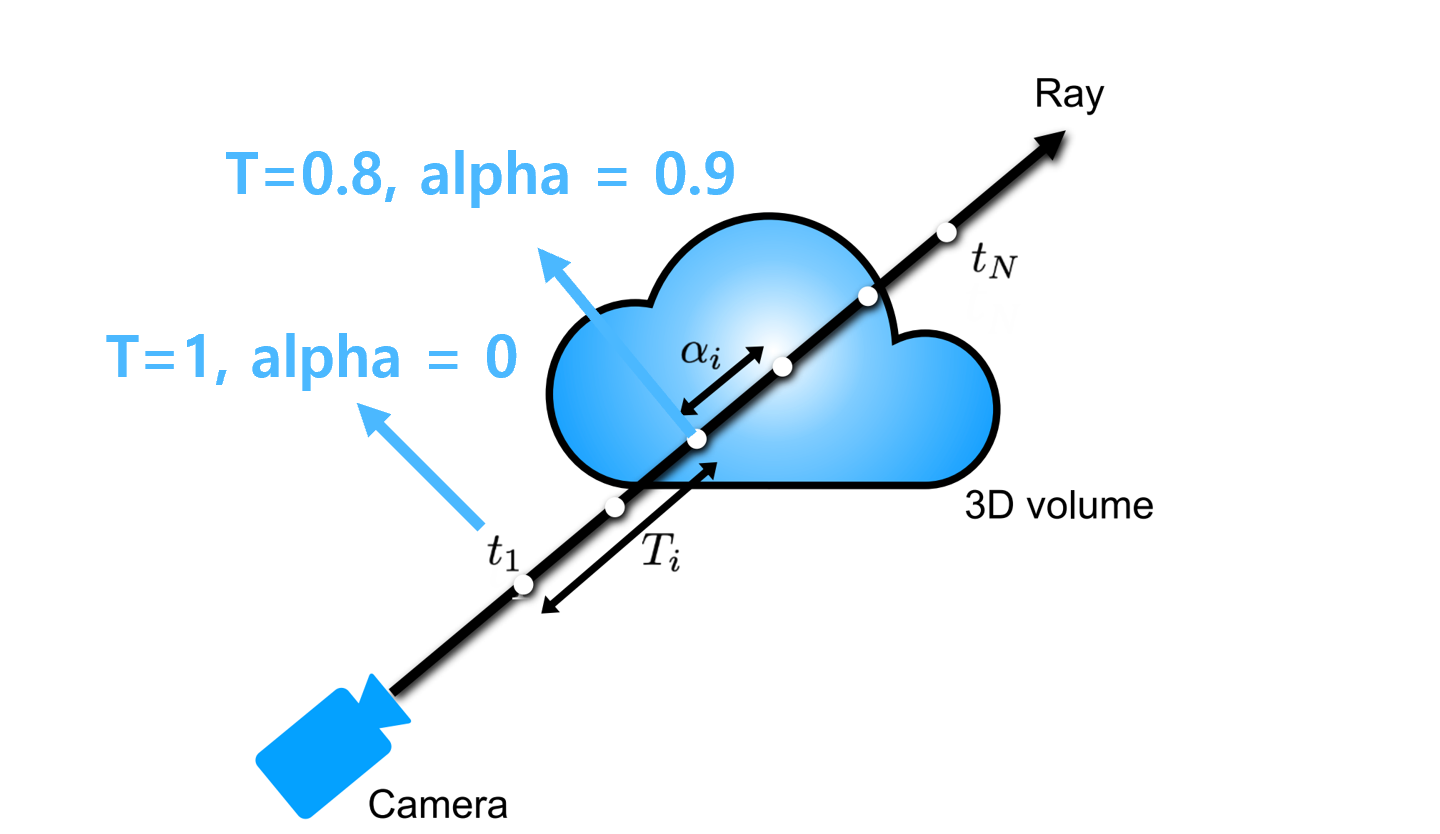
수식의 이해를 위해서 예시를 한 번 들어보겠습니다. t1의 경우 장애물이 없으니 T 즉 투과도가 1일 것입니다. 그런데 물체가 없으니 α값이 0일 것입니다. 그렇다면 color c값에 상관없이 i=1일 때 component는 0이 될 것입니다. Ray가 계속 marching 해나가면서 t3정도에서 물체를 만났다면 T가 좀 떨어져서 0.8 정도일 것이고, 밀도가 얼마나 조밀한지에 따라서 α값이 정해지게 됩니다.(대략 0.9 정도라고 가정합시다) 이때 색상 color값이 파란색이라면 i=3일 때 component값이 정해질 것입니다. 이러한 계산을 모든 샘플링 포인트들에 대해서 한 후 더해주게 되면 해당 ray가 통과하는 픽셀의 칼라 값 즉 Radiance를 얻을 수 있습니다. 그리고 이것을 Volume Rendering이라고 합니다. ( 모든 Ray, 모든 픽셀들에 대해서 이 과정을 진행하면 3d volume, scene으로부터 하나의 view image를 얻을 수 있게 되는 것입니다. )
2. NeRF's Main Components
Volume Rendering in NeRF Training
우선은 앞서도 이야기했듯 NeRF에서 Volume Rendering이 필요한 이유는 3d scene에 대한 새로운 View를 synthesis 할 때 필요합니다. 이는 학습할 때 loss가 GT image와 view synthesis image 간의 각 픽셀 값에 대해서 걸리므로 결국 NeRF에서 Volume Rendering이 필요한 이유는 Radiance를 만들어내기 위해서입니다. 특히 Training 과정에서는 predict 한 Radiance가 GT와 loss로 measure 되면서 학습을 하기 위해서인 것입니다.
그렇다면 이러한 그저 알고리즘인 Classical Volume Rendering이 어떻게 NeRF에서 사용될 수 있는지를 생각해봅시다. Volume Rendering이 Nerf에서 사용되기 위해서는 다음 2가지를 고려해야 합니다.
1. Differentiable
2. Computed Components ( color, T, α )
Differentiable
NeRF의 파이프라인에 Volume Rendering이 들어가서 새로운 픽셀 값을 계산하고 이를 gt에 대해서 loss를 걸어주기 위해서는 이러한 loss가 volume rendering을 타고 backprop 되어서 network까지 가야 합니다. 따라서, volume rendering이 미분 가능해야만 한다는 것입니다. 그런데 앞서 살펴본 Volume Rendering의 수식 구성을 보면 이는 완전히 Differentiable 함을 간단히 확인할 수 있습니다.( 가중합 & 각 component의 구성도 곱과 exponential 등 모두 미분 가능하게 이루어져 있음). 이렇게 Differentiable 하기에 Volume Rendering이 NeRF의 model이 predict 한 color와 density에 걸려 pixel radiacne를 render 하고 이를 g.t와 비교해 loss를 measure 한 후 backprop 되는 pipeline이 learnable 하게 동작할 수 있는 것입니다.
Computed Components ( color, T, α )
그런데 결국 Volume Rendering을 걸어주기 위해서 Volume Rendering의 수식에서 필요한 몇 가지 components가 필요합니다. ( 앞의 파이프라인에서는 그 요소들이 자연스럽게 NeRF에서 나온다고 가정했습니다. ) 즉, color, T, α 와 같은 요소들이 있어야 volume rendering을 걸어 radiance를 얻어낼 수 있다는 것입니다. 그런데 Volume Rendering 수식을 자세히 보면 사실 color c와 density σ만 알 수 있다면 rendering이 가능해짐을 확인할 수 있습니다.
우선 t부터 살펴보면 ray에 대해서 points를 smapling 하는 것은 컨트롤 가능한 부분이기에 t와 같은 distance에 대한 값은 제어됩니다. 그리고 alpha와 T의 수식을 보면 T는 alpha에 의해서 정의되고, alpha는 시그마인 density만 알고 있다면 정의됩니다. 따라서 Radinace C를 구하는 volume rendering 수식에서 필요한 components는 결국 각 sampling point들의 density와 color가 되는 것입니다. 따라서 위의 figure에서도 볼 수 있듯이 NeRF의 output이 color와 density인 것입니다. 이렇게 NeRF 즉 Neural Net을 통해서 얻어진 color와 density들은 volume rendering을 통해서 픽셀 값 Radiance를 결정하게 되고 이것이 loss로 measure 되어 학습이 되는 것입니다. 즉, NeRF에서 Neural Network에서 color c와 density σ 만 얻는다면 volume rendering을 걸어 Radaince를 구할 수 있다는 것입니다.
이에 기반해 NeRF에서 사용하는 Volume Rendering 식을 정리하면 다음과 같습니다.

이상적으로 view syntehsis에서 원하는 것은 continuous neural radiance field입니다. 앞에서 언급했듯 continuous 하게 synthesis를 하고 싶기 때문이죠. 그렇기에 다음과 같이 integral을 통해서 Radiacne C(r)을 정의할 수 있습니다.

하지만, 결국 이러한 수식들은 Code를 통해서 구현되어야 합니다. 그리고 컴퓨터는 discrete 한 정보를 받게 되어 있습니다. 따라서 이러한 continuous integral을 수치해석적으로 이해해야 합니다. 이를 위해서 앞서 살펴봤듯 ray위에서 3d scene 공간에 대한 point들을 sampling 하는 것입니다. 이렇게 하면 비록 discrete set of samples를 이용해서 integral을 estimation 하는 것일지라도 각 smapling 된 discrete points들이 continous position들처럼 합쳐져서 optimization 되기에 continuous scene representation이 가능하게 되는 것입니다. 따라서 이에 맞게 C(r) 즉 Radiance를 만들어내는 볼륨 렌더링 수식은 다음과 같이 수치해석적으로 표현됩니다. 이렇게 수치해석적으로 볼륨 렌더링을 구현하게 되면 코드적으로 Optimization 될 수 있게 됩니다.

이렇게 NeRF Training에서 Volume Rendering을 쓰기 위해서 Volume Rendering이 조건을 만족하고 있는지, Volume Rendering이 걸리기 위해서 필요한 components가 준비되고 있는지, 실제로 구현을 위해서 어떤 변환이 필요한지 등을 살펴봤습니다. 그렇다면 이러한 Volume Rendering은 NeRF와 명확하게 어떤 점이 다르고, 도대체 NeRF란 무엇인지를 명확히 이해해보도록 합시다.
NeRF vs Classical Volume Rendering
여기서 명확히 구분해야 할 것은 NeRF에서 하고자 하는 것과 Classical Volume Rendering의 세팅이 정 반대라는 것입니다. Classical Volume Rendering은 3d scene, volume에 대한 정보를 가지고 2d view image의 픽셀 값들을 계산하는 것이라면 NeRF는 정반대로 3d scene, volume에 대한 3d 정보를 전혀 가지고 있지 않고 이를 다양한 view에서 본 2d image들의 sparse set만을 가지고 있는 것입니다. 즉 Nerf의 input은 앞서도 이야기했듯 특정 scene에 대한 sparse 한 view들인 것입니다. 다시 말해 해당 scene( 3d object scene ) 자체를 가지고 있지 않습니다. 3차원 상의 scene에 대한 정보는 없는 상태인 것이죠. 대신에 그 scene에 대해서 여러 view에서 관찰한 view image들을 가지고 있는 것입니다. 이렇게 Nerf는 거꾸로 특정 scene을 관측한 view iamge들이 있을 건데 이 view image의 픽셀 값들이 어떻게 결정되었을지를 거꾸로 생각하는 것입니다. ( Volume Rendering의 역 )
3차원 공간의 특정 Scene이 있을 때 이에 대한 view의 특정 픽셀 값은 ray로 물체를 통과할 텐데 우리는 이 ray가 가면서 물체에 맞고 안 맞고를 알 수 없습니다. 왜냐면 우리는 이 scene에 대한 정보가 전혀 없기 때문입니다.( 공간을 모르는데, 어디에서 물체랑 부딪히는지 어떻게 알겠습니까?) 그런데 우리는 전혀 모르는 이러한 3차원 scene이 volume rendering과 같은 과정을 통해서 2d view image의 픽셀 값들이 만들어졌을 것이라는 가정으로부터 시작합니다. 즉, 내 눈에서 ray가 출발해서 3차원 물체를 지나갔다는 것을 거꾸로 3차원 공간의 광선이 날아와서 내 눈에 맺혔고 그게 view라는 것이고 이 view가 만들어질 때 volume rendering에 기반해서 즉, 광선 상의 patricle들의 color가 weight를 고려해 누적되어서 나온 결과가 지금 내 view의 픽셀 값들이라는 것입니다.
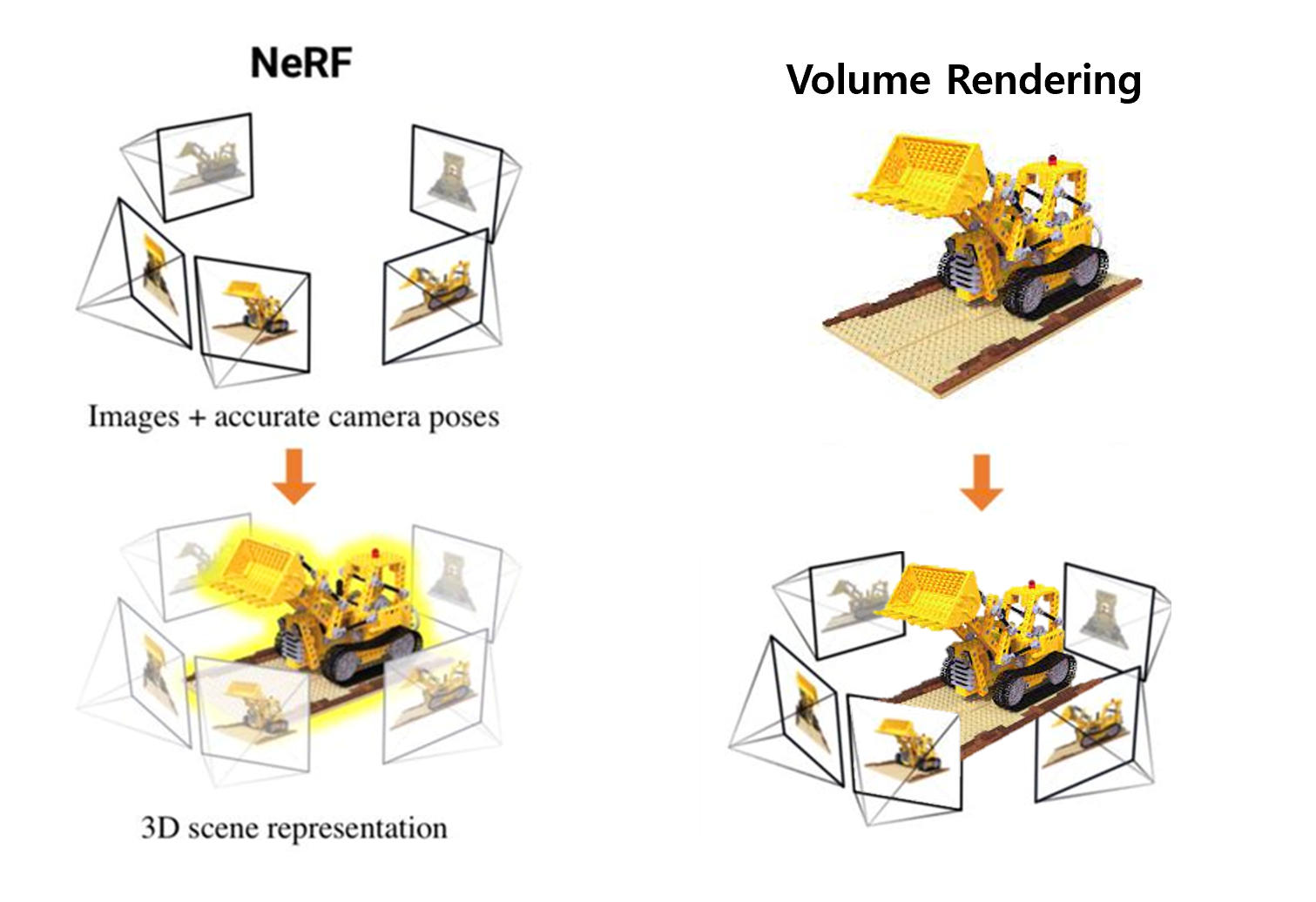
그렇다면 NeRF에서는 novel view synthesis를 위해서 Volume Rendering을 걸어주기 위해서 필요한 세팅인 3d정보가 없는데 어떻게 view synthesis를 할 수 있는 것일까요? NeRF의 핵심은 여기에 있습니다. 3d scene에 대한 이해를 Neural Net을 통해 해 주겠다는 것입니다. NeRF 논문의 title이 'Representing Scens as Neural Radiance Field for View Synthesis'인 이유가 바로 여기 있는 것이죠. 해당 scene에 대한 이해 3d 공간 정보의 이해를 Neural Net을 통해 representation 하겠다는 것입니다. 그리고 이러한 Representation은 3d의 모든 정보라기보다는 Volume Rendering을 위해 필요한 3d의 정보입니다. 결국 이러한 3d에 대해서 volume rendering을 위해 필요한 정보들이 있다면 결국 이 Neural net 즉 neural radiance field는 3d 정보를 가지고 3d scene을 이해하고 있는 것이고 그러면 volume rendering을 걸어 view synthesis를 할 수 있다는 것입니다. 즉, view synthesis를 하기 위해서는 volume rendering이 걸려야 하는 것인데 우리는 3d공간을 모르니 color와 density값들을 모릅니다. 역으로 생각하자면 이 값들만 안다면 volume rendering을 통한 view synthesis가 가능해집니다. 그 말은 즉, NeRF의 세팅에서 view synthesis를 하기 위한 3d 공간을 이해하고 있다는 것은 color와 density값들을 알고 있다는 것으로 충분히 representation 될 수 있다는 것입니다.
NeRF : Neural Radiance Fields
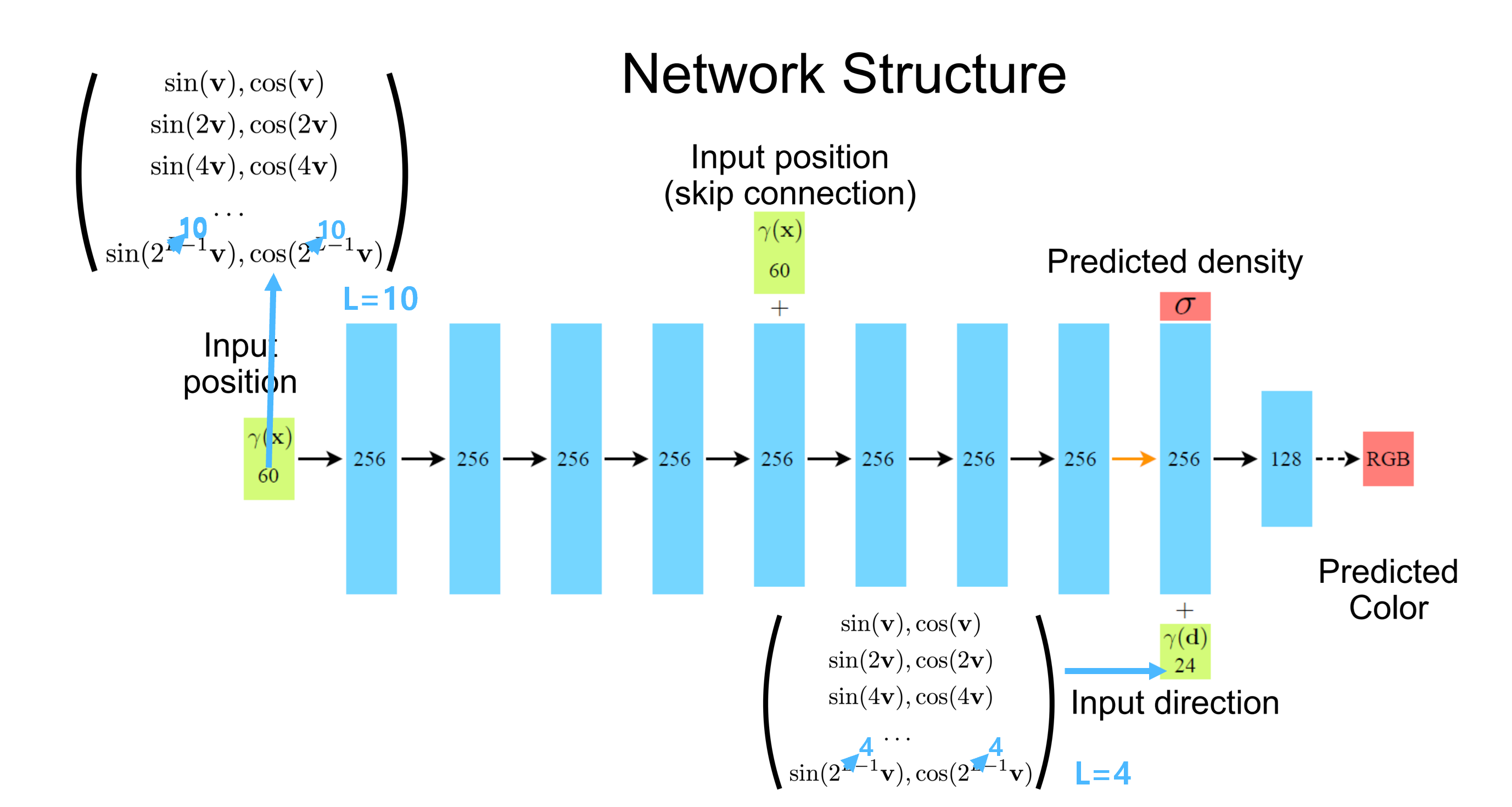
이때 사용하는 Neural Net( 결국 함수 Funciton ) 즉, volume rendering을 걸기 위해 빈 3d 공간의 ray상의 sampling points를 input으로 넣어 volume rendering에 필요한 color와 density를 output으로 뽑아내는 function을 NeRF(Neural Radiance Field)라고 합니다. Neural Radiance Field는 빈 공간상에서 가상의 Ray를 따라갔을 때 그 위의 sampling points의 x, y, z coordinates와 해당 Ray의 방향 정보인 viewing direction ( θ, φ )로 이루어진 5d coordinates를 Input으로 넣어 해당 point의 color와 density값을 return 하는 function입니다. 이렇게 color와 density들을 안다면 radiacne를 계산해낼 수 있는 것이니 NeRF가 Neural Radiance Field인 것입니다. 이러한 color와 density라는 3d공간에 대한 정보를 NeRF가 가지고 있기에 neural scene representation이라고 하는 것이고요. ( NeRF는 결국 아래 Figure인 것입니다. MLP를 쌓아 Neural Radinace Field를 구성해주게 되며 다음과 같은 Input, Output을 가지는 것이죠. 왜 input , output이 저래야 하는지는 충분히 이해가 갔을 것이라고 생각합니다. )
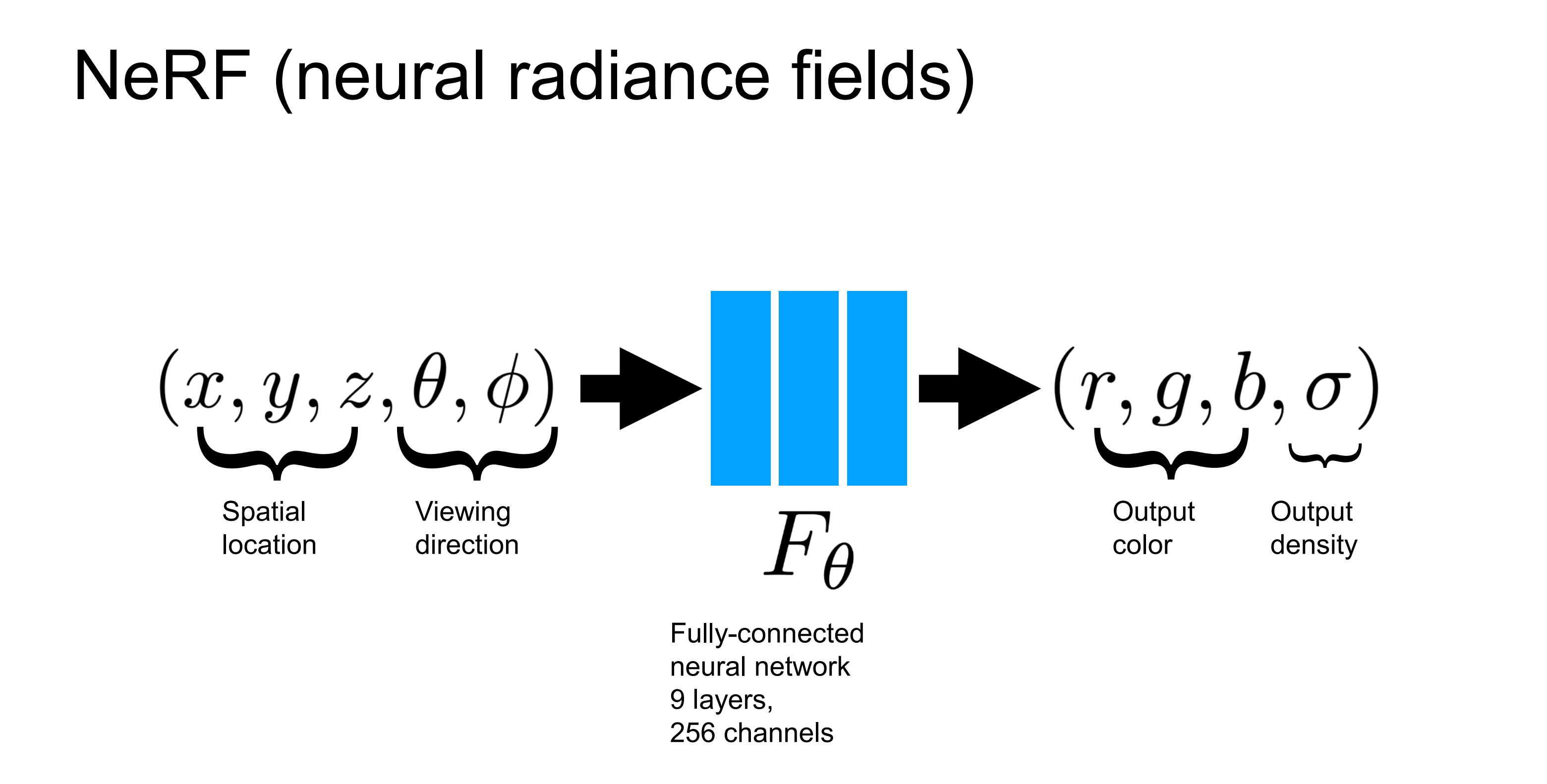
따라서 앞서 Volume Rendering이 걸리기 위해서 필요했던 3d 공간상의 각 point들의 color값과 density값을 predict 할 수 있는 Neural Network를 학습시키게 되면 이것이 결국 radiance field를 이해하고 있는 neural net으로부터 나온 Neural Radiance Field이고 이러한 네트워크가 3d scene representation을 한다는 즉, 3d scene에 대한 정보를 담고 있다는 것입니다. ( color와 density값이라는 3d상의 정보만 있다면 volume rendering을 통해 view synthesis를 해서 radiance field를 얻을 수 있으니, 이러한 NeRF가 scene representatoin as Neural Radiance Field라는 것이다. )

그래서 결국 NeRF의 Neural Radiance Field는 특정 Radiance를 결정하는 ray위의 sampling points에 대한 위치정보(x, y, z)와 해당 ray의 시선 방향 정보(viewing direction= θ, φ)를 input으로 받아 color와 density를 output으로 뽑은 후 volume rendering을 걸어 나온 radiance값을 gt의 pixel값과 비교해 비슷해지도록 하는 loss를 minimize 하도록 학습되면서 해당 scene에 대해서 volume rendering결과가 잘 나오는 즉, T alpha c 값을 잘 얻을 수 있도록 하는 Radinace Field를 잘 이해하는 Neural Net이 학습된다는 것입니다. 그렇기에 scene representation으로써 Neural Radiance Field가 될 수 있는 것이죠. 즉 이러한 Radiance field만 알고 있다면 볼륨 렌더링을 걸어서 3d scene에서 특정 view를 projection 하는 것처럼 synthesis 할 수 있으니 3d scene representatoin을 충분히 잘한다는 것입니다.
이때 구현체를 고려하더라도 NeRF에서 Radiance를 render하는 과정을 명확히 이해해두는 것이 좋습니다. 논문에서는 다음과 같은 순서로 적혀있습니다.

즉, 첫 번째로 현재의 빈 3d 공간에 대해서 ray들을 날릴 것이라는 가정하에 동작하니 이러한 빈 공간에 view에 대한 ray들을 날려두고 이 위에 sampling points들을 marching해두게 되는 것입니다. ( Ray bundle과 그 위의 sampling points를 미리 준비 ) 두 번째로 이러한 points와 이때의 ray의 viewing direction을 5d coordinates로 정리해 NeRF network에 입력해주게 되고 출력으로 color와 density를 뽑아냅니다. 마지막으로 classical volume rendering을 걸어 color와 density들을 accumulate해서 2d image로 rendering합니다. ( 특히 처음에 ray bundle과 points 세팅하는 것을 꼭 확인해둡시다. )
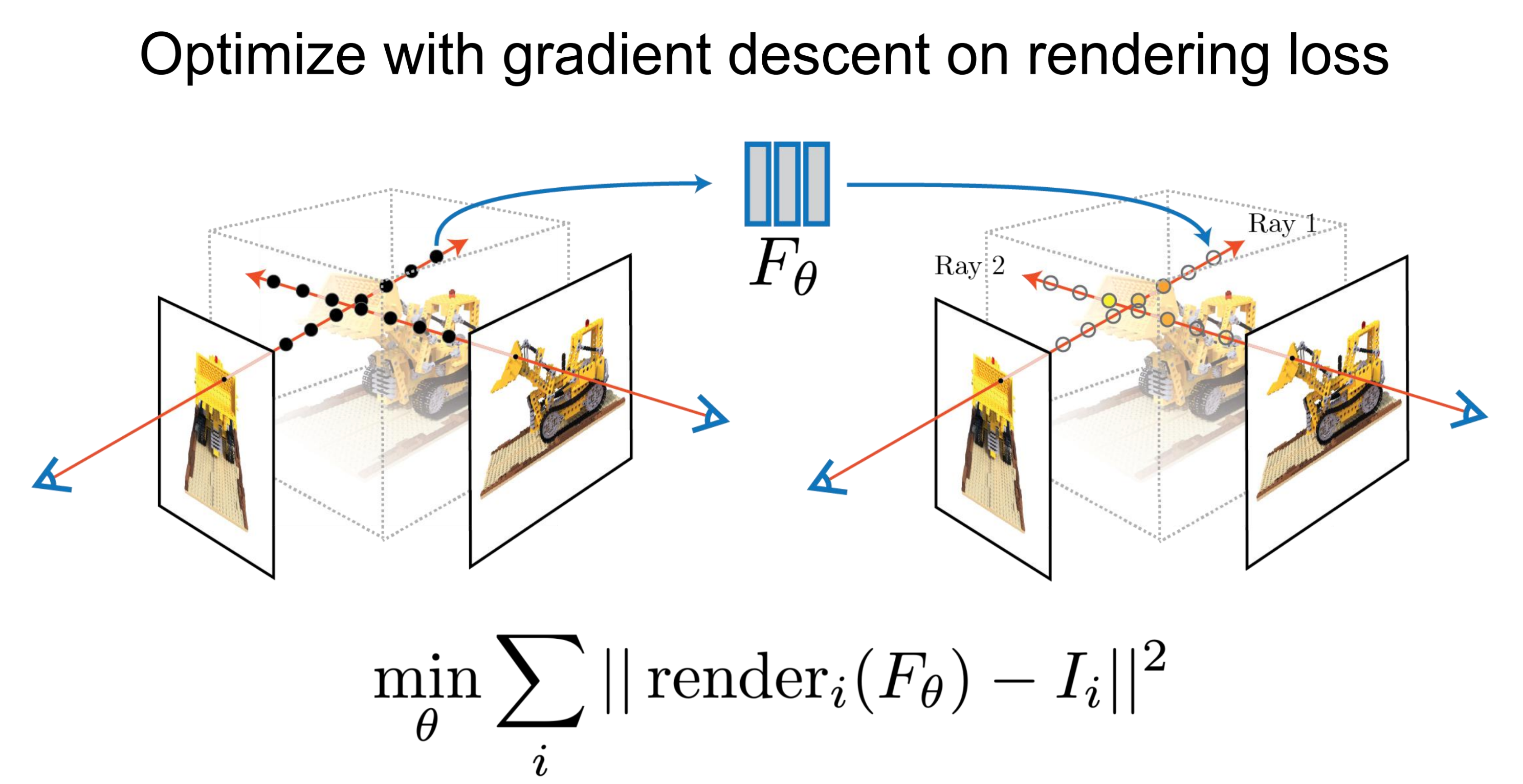
즉, 위 figure상에서 검은 점들( sampling points)에 어떤 color, density를 가지고 있는지 3d scene에 대한 정보는 없지만 이것들이 합쳐지면 알고 있는 2d view image의 pixel값이 된다는 것이니, 이러한 ray를 여러 pixel들 & 여러 view에 대해서 날리면 ( 충분한 sparse view ) 각 샘플링 포인트들에 대해서 충분히 잘 해당 포인트의 color와 density를 예측하도록 학습된다는 것입니다. 따라서 잘 학습된 F가 있다면 처음 보는 View에서의 5d coordinates도 F를 거쳐 정확한 color와 density값을 뱉을 것이기에 volume rendering을 통해서 novel view synthesis도 가능해진다는 것입니다.
한 가지 명확히 할 점은 이 NeRF는 결국 특정 scene에 대해서 overfitting 되는 네트워크라는 것입니다. 포클레인에 대해서 학습된 NeRF를 드럼에 가져가면 잘 못할 것이라는 것입니다. 결국 이 F라는 Neural Radiance Field가 이해하는 것은 특정 scene에 대한 sparse 한 view들을 통해 학습함으로써 각 입력 이미지들이 표현하는 특정 장면입니다. 즉, 다른 장면을 그려낼 수 없다는 것입니다. 다시 말해 특정 Scene에 대해서 (여기서는 포크레인 ) Overfitting 되는 네트워크인 것입니다. 이것이 가능한 이유는 결국 NeRF의 세팅 상에서 수많은 point들에 대해서 NeRF가 학습되기 때문입니다. ( Sparse 한 view이지만, 각 view의 모든 픽셀들의 ray위에 sampling points가 존재하고 이것들이 입력으로 들어간다고 생각하면 엄청나게 많은 points에 대해서 NeRF가 학습되는 것이다. => 전체 View를 한 번 돈다고 할 때 num_view * view_width*view_height*num_sampling_points 만큼을 한 번 보는 것이다. 그렇게 되면 각 픽셀이 GT가 되니 이미지 하나에도 pixel개수가 많은데 여러 view가 있으니 GT도 엄청 많아지게 되는 세팅인 것이다. 이렇게 엄청 많은 data들을 통해서 네트워크가 학습되는 것이다. )
Network Structure
이러한 Neural Radiance Field Function F에 대해서 네트워크 구조를 살펴보면서 더 깊게 이해해보겠습니다. Network Structure는 다음과 같습니다. 앞서 언급했던 대로 MLP레이어로 구성되어 있습니다. 하나하나 자세히 짚으면서 이해해보도록 하겠습니다.
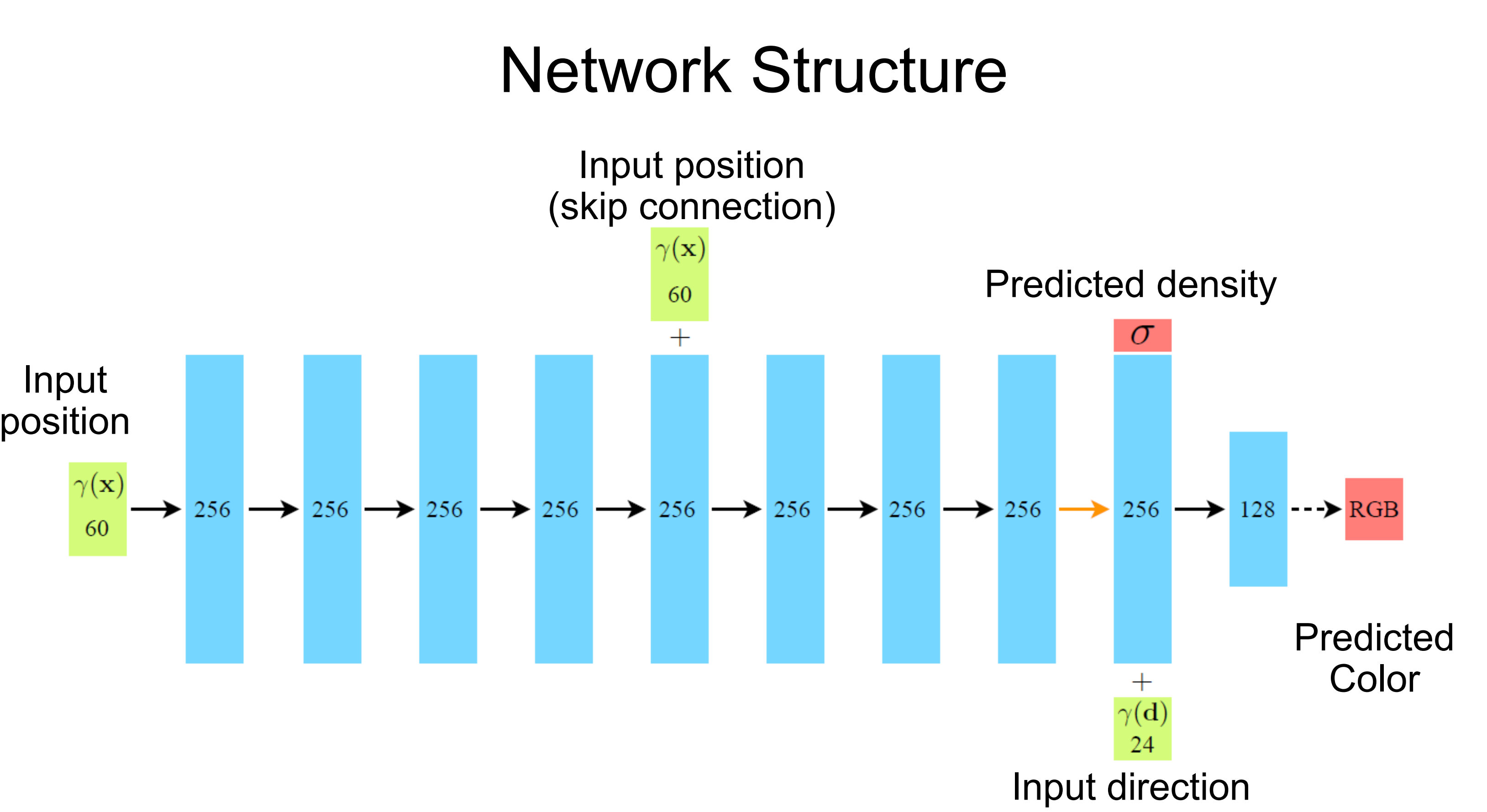
- MLP 사용의 이유 : 이때 왜 CNN이 아닌 MLP인지를 이해할 필요가 있습니다. query로 날아가는 sampling input position들은 어떤 순서로 들어갈지 모릅니다. 따라서 순서에 상관없이 잘 처리할 수 있어야 합니다. ( Permutation Invariant ) 따라서 CNN처럼 Inductive Bias로 spatial 한 정보적 편향을 가지고 있다면 안 되는 것입니다. 이러한 Permutation Invaraint에 적합한 네트워크 구조는 대표적으로 MLP와 Transformer일 것입니다. 그래서 vanila NeRF에서는 mlp를 쓰고 있고 이러한 network structure를 그냥 transformer로 교체한 NeRFormer도 있습니다.
- Input position & Input direction : 초기 Input으로는 x, y, z floating point coordinates만 받게 됩니다. 그리고 8번째 mlp layer까지 거친 후 density만 prediction 하게 됩니다. 이러한 구조를 가지는 이유는 공간상의 엄청 많은 points들을 학습함으로써 mlp 8겹 정도를 쌓으면 해당 points의 density를 충분히 예측할 수 있도록 학습이 될 것이라고 생각했기 때문입니다. ( points가 엄청 많이 학습되기 때문이겠다 ) 즉, 3d scene의 density자체를 이해한 것입니다. ( 당연하게도 이게 가능한 이유는 이 밀도를 이용해 volume rendering 한 후 loss를 걸었기 때문이겠다. ) 그래서 지금까지 density를 충분히 잘 예측하도록 학습이 된 상태라면 특정 위치(x, y, z)의 density를 물어보면 알려줄 정도로 학습이 되었다는 것입니다.
- Input direction : 앞서 같은 지점을 각각 다른 방향 view에서 봤을 때 다른 색상으로 보이는 물리적 현상을 이해했습니다. 이를 고려하면 color prediction에 있어서는 viewing direction( θ, φ ) 정보가 필요합니다. 저자들은 이미 3d scene에 대해서 충분히 잘 이해하도록 8개의 mlp를 학습시켰고, 이건 density를 잘 예측할 수 있을 정도로 3d scene을 잘 이해된 상태입니다. 하지만, specular term이 의미하는 물리적 현상을 고려해 color를 예측하기 위해서는 해당 scene의 정보에 대해서 이미 잘 학습된 상태( scene에 대한 이해 )에서 viewing direction을 줘서 한 층만 추가해줘도 color값을 잘 예측하도록 학습될 거라는 것입니다.
- 즉, 지금까지 x, y, z에 대해서 이해했는 상황이 되어서 3d scene을 이해했다면 이제는 view direction정보를 추가로 이용함으로써 각 view에서의 radiance( view direction마다 다른 color를 메모링 하도록 네트워크를 설계한 것이다. )를 잘 계산하도록 points들의 color값을 학습한 것입니다.
- 다시 말해 3d scene만 이해하고 있는 상태는(8개의 mlp를 통과한 상태) 각 x, y, z들에 대해서 잘 이해하고 있어서 혹은 그 3d scene을 잘 이해하고 있어서 특정 위치에 밀도를 물어보면 알려줄 정도로 학습된 상태라는 것입니다. 그래서 실제로 각각 다른 방향에서 같은 지점을 볼 때 다른 칼라 값으로 보이는 물리적 현상을 고려할 때 이걸 위해서는 칼라 값을 얻기 위해서는 각 방향 정보가 필요한 것이기에 추가적인 쿼리로 즉 어떤 방향(view)인지를 알려줘 이러한 물리현상이 고려된 color값을 예측하도록 학습할 수 있다는 것입니다.
- Skip Connection : 5번째 layer에서 Skip Connection을 주기에 316차원의 값이 다음 mlp레이어의 input으로 들어가게 됩니다. 이러한 skip connection은 이전의 x, y, z floating point로 neural net을 통해 occupancy를 predcition 하도록 했던 연구들의 영향을 받은 것입니다.
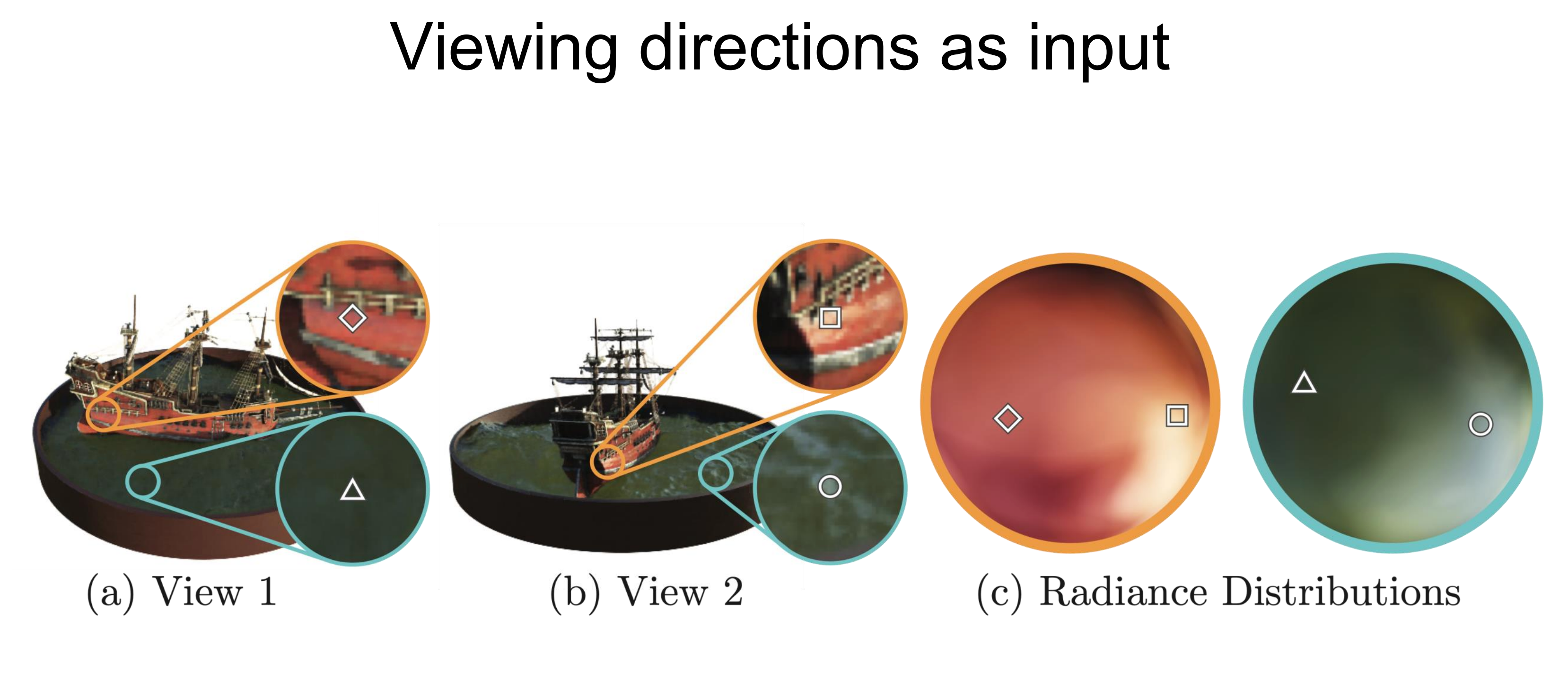
이렇게 학습이 되었기에, NeRF는 같은 위치를 다른 방향에서 관찰했을 때 다른 색상으로 보이는 물리적 현상을 매우 잘 표현할 수 있게 됩니다. 위의 Figure는 특정 scene의 같은 위치를 서로 다른 view에서 봤을 때의 색상들의 분포를 표현한 것입니다 -(c). 즉 (a), (b)에서 표현되고 있는 특정 지점에 대한 색상을 엄청 많은 view들에서 관찰했을 때의 분포를 아래와 같이 시각적으로 표현한 거라는 것입니다. 이러한 분포는 NeRF의 결과에 대한 색상 분포가 다양하게 나오는 것으로 미루어 볼 때 앞서 언급했던 Phong Reflection Model의 specular term이 잘 표현되는 것입니다. 즉, NeRF가 이러한 물리적 현상을 매우 잘 표현하고 있다는 것입니다.
Implicit Representation
이때 앞서 잠깐 언급했던 scene representation을 implicit representation이라고 표현하는 경우가 많습니다. 후속 연구나 관련 분야에서 Implicit Representation이란 말은 많이 사용되기에 명확히 이해해두는 것이 좋을 것 같습니다. 왜 Implicit Representation이라고 하는지 지금부터 살펴보도록 하겠습니다. NeRF에서는 3d공간을 명확히 안다기(explicit representation)보다는 view synthesis를 위해서 필요한 scene representation을 얻을 수 있도록 네트워크가 학습된다는 점에서 NeRF의 Neural Radiance Field를 Implicit Representation이라고 합니다. 특정 scene에 대해서 mesh나 point cloud과 같은 explicit representation을 하는 것이 아닌 각 point에 대한 공간 정보를 5d coords를 input으로 받아 color와 density를 뽑아내는 Neural Network로 implicit 하게 나타내고 있다는 점에서 NeRF의 Scene Representation을 implicit representation이라고 합니다. 즉, 이러한 Neural Network가 3d scene에 대한 정보를 담고 있다는 것입니다. ( Nerual Network가 representation 할 수 있는 것은 image 뿐 아니라, video, 3d object 등 다양하다 ) 일반적이게 mesh와 같은 자료구조를 이용해 explicit 하게 표현하는 것이 아닌 neural net이 정보를 담고 있다는 것을 통한 represenatation인 implicit representation이라는 것입니다. ( Implicit representation 자체의 정의는 Neural Network가 어떤 정보를 저장하고 있다는 것을 의미한다. )
물론 더 나아가서 Implicit Function 즉, 음함수를 떠올려보면 이러한 Implicit Representation을 이해하기 쉽습니다. 일반적으로 image를 학습한다고 하면 image자체를 입력으로 넣게 됩니다. 하지만, NeRF같은 경우 해당 이미지의 coordinates를 넣어서 학습시키게 됩니다. 즉, spatial coordinates가 input인 것입니다. 따라서 NeRF와 같이 spatial coordinates를 input으로 받는 모델을 Implicit Function이라고 정의할 수 있고, 이 Function이 Neural Network 여서 각 coordinates가 담고 있을 값 ( RGB or density , ... )을 representation한다고 할 때 이를 Implicit Neural Representation이라고 합니다.
- General : F(x) , x = image(rgb values tensor)
- Implicit : F(x,y,z)
3. Optimizing Methods
지금까지 Scene을 Neural radiance Field로 Modeling 하는 데 그리고 이러한 Representation으로부터 Novel View를 Synthesis혹은 rendering 하는 데에 필요한 core components들을 살펴봤습니다. 하지만, 여기까지 만으로는 high resolution complex scene에 대한 performance quality가 떨어집니다. 이를 위해서 저자들을 추가적으로 2가지 optimizing method로 1. Positional Encoding 2. Hierachical Sampling을 제시합니다. 이 둘은 이후 연구들에서도 대부분 사용되고 있으니 주의 깊게 살펴보는 것이 좋습니다.
Positional Encoding
지금까지 살펴봤던 대로 NeRF를 구성하여 학습시킨 후 확인해보면, 잘 되지만 Blur 한 결과들을 내놓는 것을 확인할 수 있습니다. 이러한 Naive 한 NeRF의 결과가 이렇게 나오는 이유는 Deep Neural Network가 lower frequency functions에 bias 되어 있기 때문입니다. 즉 DNN 자체가 low frequency 정보를 잘 학습하도록 bias 되어 high frqeuncy를 가진 image들은 잘 학습하지 못한다는 것입니다. 이는 Fourier Features Let Networks Learn
High Frequency Functions in Low Dimensional Domains 논문 잘 나와있습니다 ( 추후 리뷰글 작성 예정 이를 참고하자 )

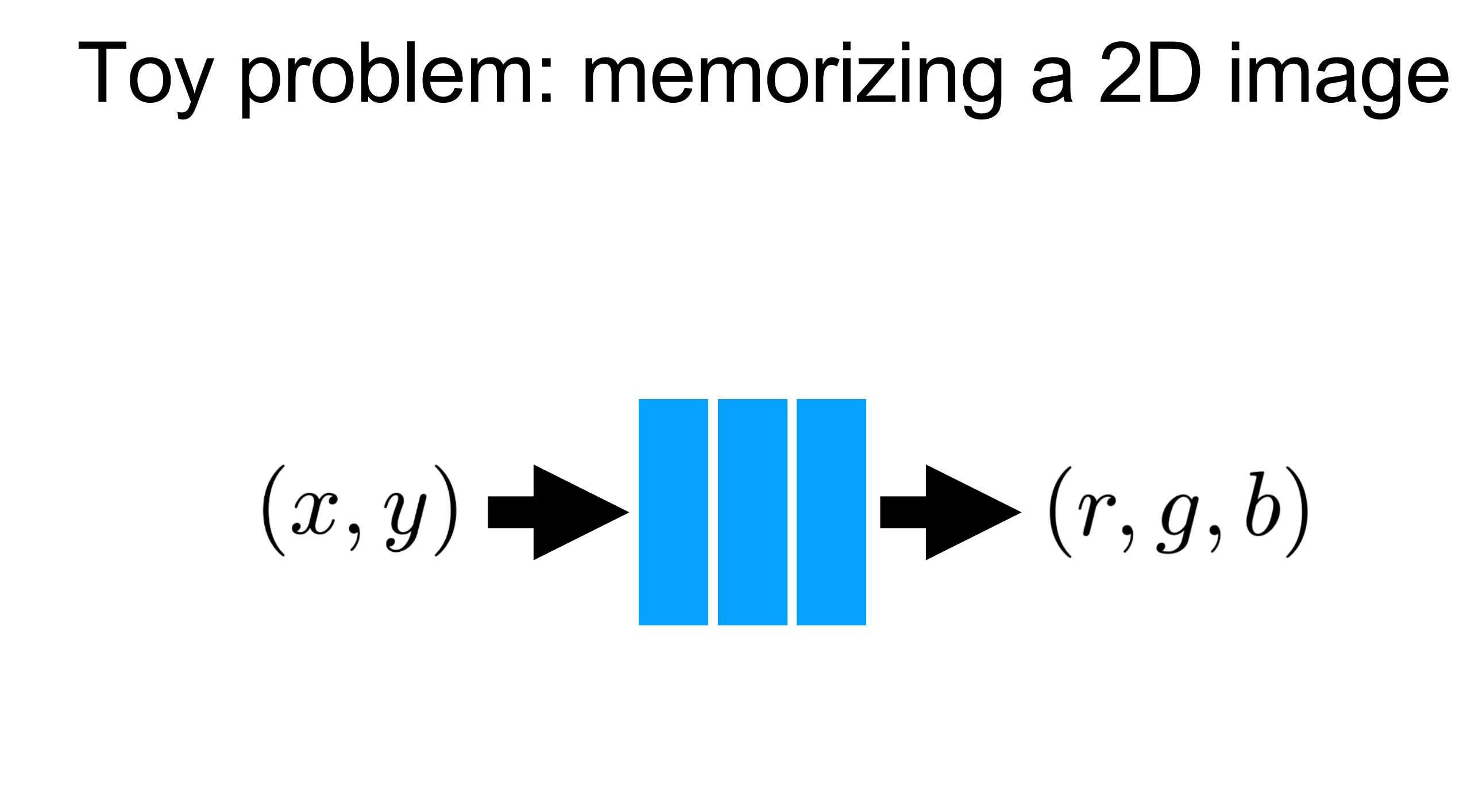
간단히 확인해보자면 지금이 NeRF는 input으로 일반적인 computer vision문제처럼 image자체 즉, rgb color로 된 텐서를 넣는 것이 아닙니다. x, y, z라는 floating points를 input으로 넣습니다. 이처럼 위 논문의 저자들은 특정 image에 대해서 x, y 좌표계를 넣고 뉴럴 넷을 통과해서 rgb color를 예측하도록 학습을 시켰습니다. 즉, 특정 image를 외우도록 학습시킨 것입니다. 하지만, 뉴럴 넷이 잘하지 못하고 blur 하고 왜곡된 결과를 만들어내는 것을 볼 수 있었습니다. 이러한 결과를 바탕으로 저자들은 일반적인 DNN은 입력으로 floating point가 들어갈 때 low frequeny에 bias 되게 학습된다는 즉, 디테일을 표현하지 못하고 전체적인 representation만 학습한다는 것을 확인했습니다.

따라서 저자들은 이러한 Floating points input을 high frequency function을 통해서 higher dimensional space로 mapping( fourier feature mapping 혹은 Positional Encoding - fourier feature mapping에 포함되는 개념)해서 network에 넣어줌으로써 high frequency variation을 잘 capture 하도록 학습시켜야 한다고 주장합니다. 실제로 2d 사자 이미지를 외우도록 학습시킬 때 이러한 mapping을 해주지 않은 것(naive)과 해준 것을 비교해보면 훨씬 non-blur 하고 정확한 결과를 얻는 것을 확인할 수 있습니다.
( https://youtube.com/clip/UgkxpoU0XhG83kAgCODFtgpspI3x6qzcax51 )

이는 NeRF에서도 동일하게 적용됩니다. NeRF에서 Neural Radiance Fields F 즉, Neural Network에 넣기 전에 high frequency mapping을 해주는 positional encoding을 해주자는 것입니다. 물론 Transformer에서 positional encoding은 token들 간의 위치 정보를 주기 위해서 사용되었다면, 여기서의 positional encoding은 contiuous input coordinates를 high frequencty mapping을 해주는 역할로 사용된 것입니다.( fourier transform이 아닌 postional encoding이라고 표현하는 이유는 transformer가 토큰의 위치 정보를 전달하기 위해서 사용한 것처럼 각 input coordinates의 위치 정보를 준다고도 이해할 수 있다. )

이러한 Positional Encoding은 다음과 같이 Fourier Transform처럼 sin, cos 함수들의 조합으로 mapping 해줬더니 위처럼 네트워크가 잘 이해하기 시작했다는 것입니다. 위 논문 이후로 floating point를 input으로 넣어야 할 때 sin, cos의 조합으로 mapping 후 네트워크에 넣는 것이 정형화되어 사용되고 있습니다.

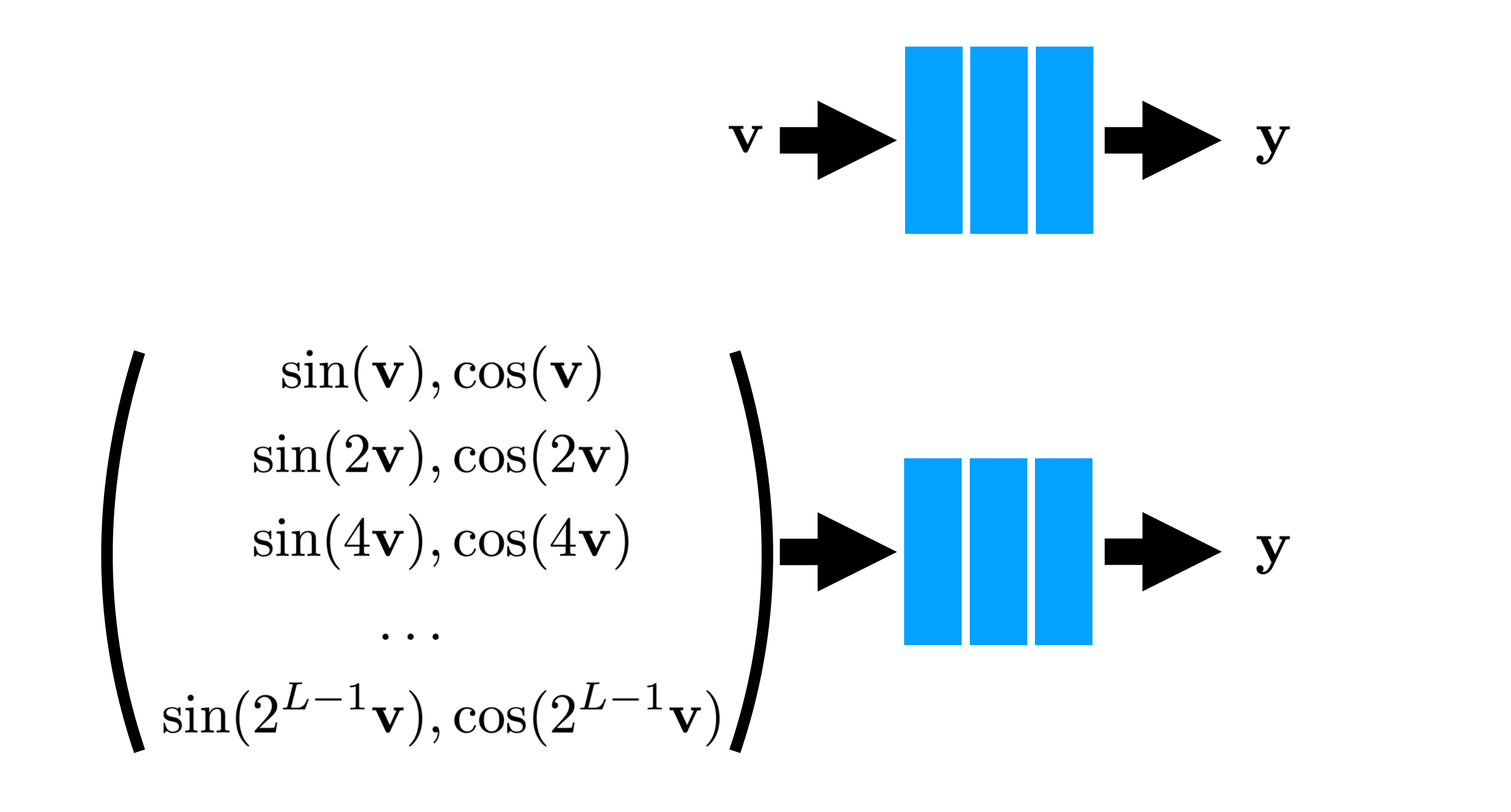
그러면 비로소 NeRF의 network structure에서 분명 5d coordinates를 넣는데, 60차원 input이었던 이유를 확인할 수 있게 됩니다. x, y, z coordinates의 경우 sin10개 cos 10개씩 즉 L=10으로 하고, viewing direction의 경우 각각 4개씩 즉 L=4로 mapping 하는 것입니다. 그러면 Input이 60차원이고 중간에 viewing direction을 넣어줄 때 24차원인 것을 이해할 수 있게 되는 것입니다. ( 물론 viewing direction의 경우 일반적으로 위도 경도라고 해서 θ, φ 로 설정하는데 이는 구현이 힘들기 때문에 이를 3차원의 unit vector로 바꿔서 표현한다. 따라서 8*3이 되어 24가 된다. )
이는 NeRF에서도 실험 결과들을 비교함으로써 확인할 수 있습니다. No View Dependence는 위 network structure에서 inpuit direction정보를 넣어주지 않았을 때의 결과이고, No Positional Encoding은 positional encoding을 통한 high frequency mapping을 해주지 않았을 때의 결과입니다. 확실히 positional encoding을 해주는 것이 좋은 결과 즉 high frequency image도 잘 표현하는 것을 확인할 수 있습니다.


Hierarchical Sampling ( two pass sampling )
NeRF에서는 high-frequency representation을 위해서 ray위에서 points를 efficient 하게 sampling 하는 것을 optimizing 하고자 합니다. 이를 위해서 Vanila NeRF에서는 이전에서도 많이 사용됐고, 이후에서도 많이 사용되는 테크닉이지만 Hierarchical sampling 즉 Two Pass Sampling을 사용합니다. 이러한 two pass sampling을 사용하는 이유에 대해서 이야기하기에 앞서 기존의 stratified sampling을 먼저 떠올려봅시다. 현실은 continuous 합니다. 즉, 지금 샘플링하는 것과 같은 discrete 한 자연현상은 존재하지 않습니다. continuous 한 현실을 이렇게 discrete 하면서도 균등한 간격으로 sampling 하게 되면 현실을 잘 반영하지 못할 것입니다.(Nyquist Sampling Theorm을 떠올려 볼 수도 있겠습니다.) 현재 sampling 하는 points들의 목적은 결국 3d scene 거기서도 object가 있는데 이것을 명확히 이해하고자 하는 것입니다. 이러한 목적성에 맞게 잘 샘플링하는 방법은 object 물체와 마주치는 위치에서 최대한 많이 샘플링하는 것입니다. ( 우리는 특정 scene에 대한 이해를 원하는 것이므로 ) 즉, ray 상의 샘플링 위치가 밀도가 높은 곳일수록 정확한 radiance값을 얻을 수 있다는 것입니다. 하지만, 우리는 어디에 물체가 존재하는지 즉 3d 공간에 대한 정보를 가지고 있지는 않습니다. 따라서 어떤 부분에서 물체와 마주치는지 모르는 것입니다. 이를 고려하기 위해서 two pass rendering을 하게 됩니다.
3d공간에 대한 밀도 분포가 하단의 붉은 실선의 분포와 같다고 가정해봅시다. 처음 즉, 1 pass에서는 기존처럼 stratified sampling을 하고, 저자들은 이를 coarse sampling이라고 합니다. 이때 NeRF는 균등하게 샘플링된 points에 대해서 output으로 density를 뽑아내게 됩니다.
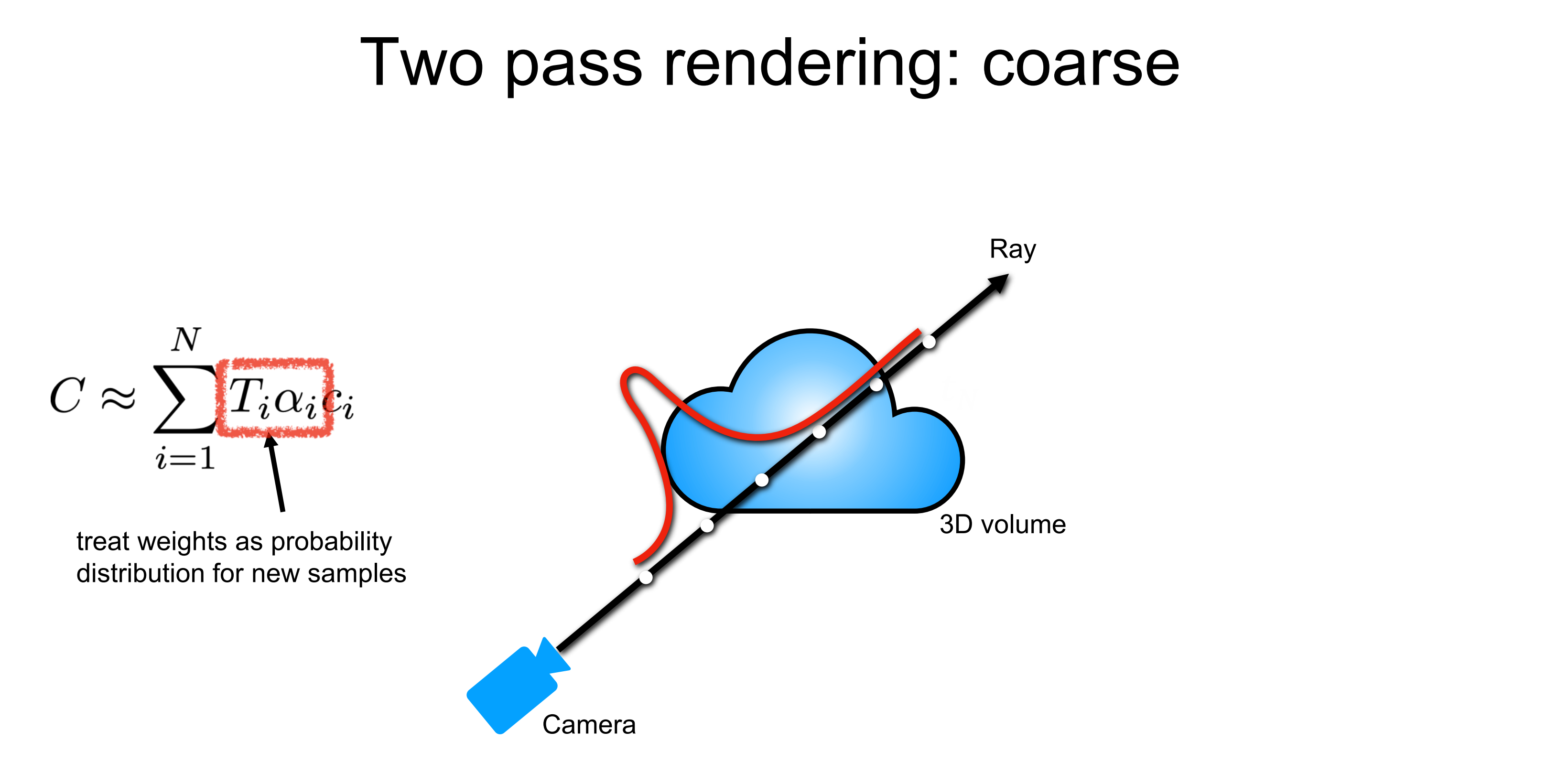
그리고 2번째 pass 즉, fine sampling은 밀도의 분포를 고려해서 밀도가 높은 곳 근처에서 샘플링을 하도록 합니다. 즉, 아직 덜 학습되어 정확하지는 않을지라도 density를 학습해 어디에 물체가 있을지를 어느 정도 학습했다면 여기서 뽑아낸 density에 기반해서 밀도가 더 높은 지점들 근처에서 샘플링을 더 많이 하게 되면 더 좋은 목적성에 맞는 샘플링이 될 거라는 것입니다. 즉 1 pass에서는 coarse 한 sampling을 했다면 이번에는 밀도를 고려해 좀 더 local 한 부분에 집중해 fine 하게 sampling 하겠다는 것입니다.
Importance Sampling
그런데 이렇게 밀도가 높은 부분들 근처에서 많이 샘플링하는 것은 어떻게 하는 것일까요? 이처럼 특정 value가 높은 혹은 확률 값이 높은 곳에서 샘플링을 많이 하게 하는 방법을 Importance Sampling이라고도 합니다. 이러한 Importance Sampling의 구조는 매우 간단하고 통계의 기본에 있습니다. 통계학을 배우면서 PDF를 많이 들어봤을 것이다. 이러한 PDF( Probability distribution function )가 하나 있다고 가정해봅시다. 이때 이 PDF를 CDF ( Cummulative distribution function )로 변환하는 것은 쉽습니다. 그냥 누적시키면 되는 것입니다. 그러면 이 CDF에서 y축을 등간격으로 샘플링해봅시다. 즉, 누적 값이 0.1인 부분, 0.2인 부분,... 으로부터 거꾸로 hit 한다는 것입니다. 그렇게 되면 바로 이전 구간과 간격 차이가 클수록 많은 hit이 생깁니다. 다시 말해 유독 높은 값을 지닌 구간 즉, importance 한 구간이 hit이 높다는 것입니다. 이를 활용하면, 확률이 급격히 높아지는 부분에서 많이 샘플링하는 Importance Sampling을 할 수 있게 되는 것입니다. ( NeRF기준으로는 density가 확 높아지는 부분 = 물체를 갑자기 만난 부분 )
결국 우리가 가지고 있는 importance value의 분포를 CDF로 바꾼 후에 hit의 개수에 따라 importance를 정하고 이러한 Importance에 기반해 importance가 높은 곳 근처에서 많이 샘플링을 하도록 한다는 것입니다.
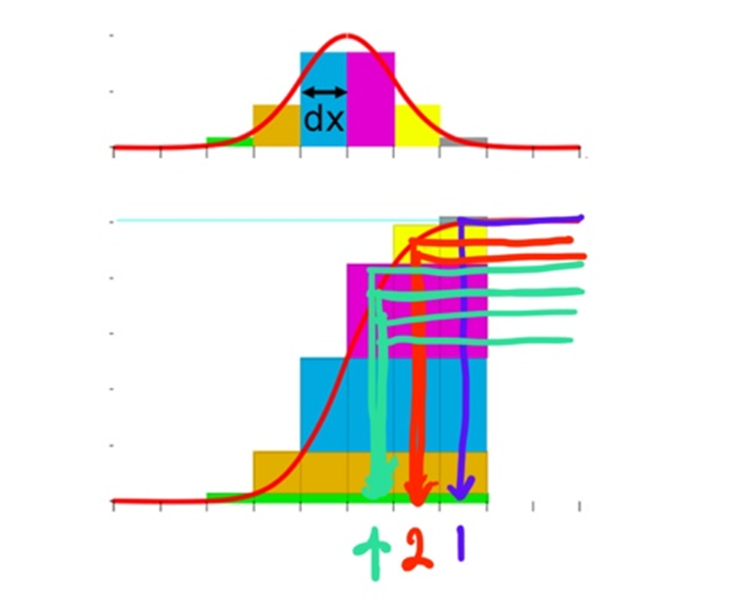
따라서 fine sampling에서는 coarse sampling에서 나왔던 C(r)를 구하기 위한 가중치 w에 기반해서 importance sampling을 하게 됩니다. 그 결과가 다음과 같은 빨간색 point들입니다. density distribution을 고려할 때 density에 기반한 importance sampling이 이루어졌음을 직관적으로 확인할 수도 있습니다. 물론 fine sampling시에는 coarse sampling에서 사용했던 stratified sampling도 같이 하게 됩니다. 즉, 1 pass에서 흰색 포인트들만 샘플링했다면 2 pass에서는 흰색 포인트들 + 붉은색 포인트들을 모두 샘플링한다는 것입니다.
이렇게 각각의 pass는 각각의 NeRF 네트워크를 학습시키게 됩니다. 논문에서는 각각을 coarse network와 fine network로 정의하고 있습니다. 결국은 2 pass sampling을 통해서 NeRF를 density에 기반해서 더 정확히 radiance field를 학습하도록 optimization 하는 것입니다.
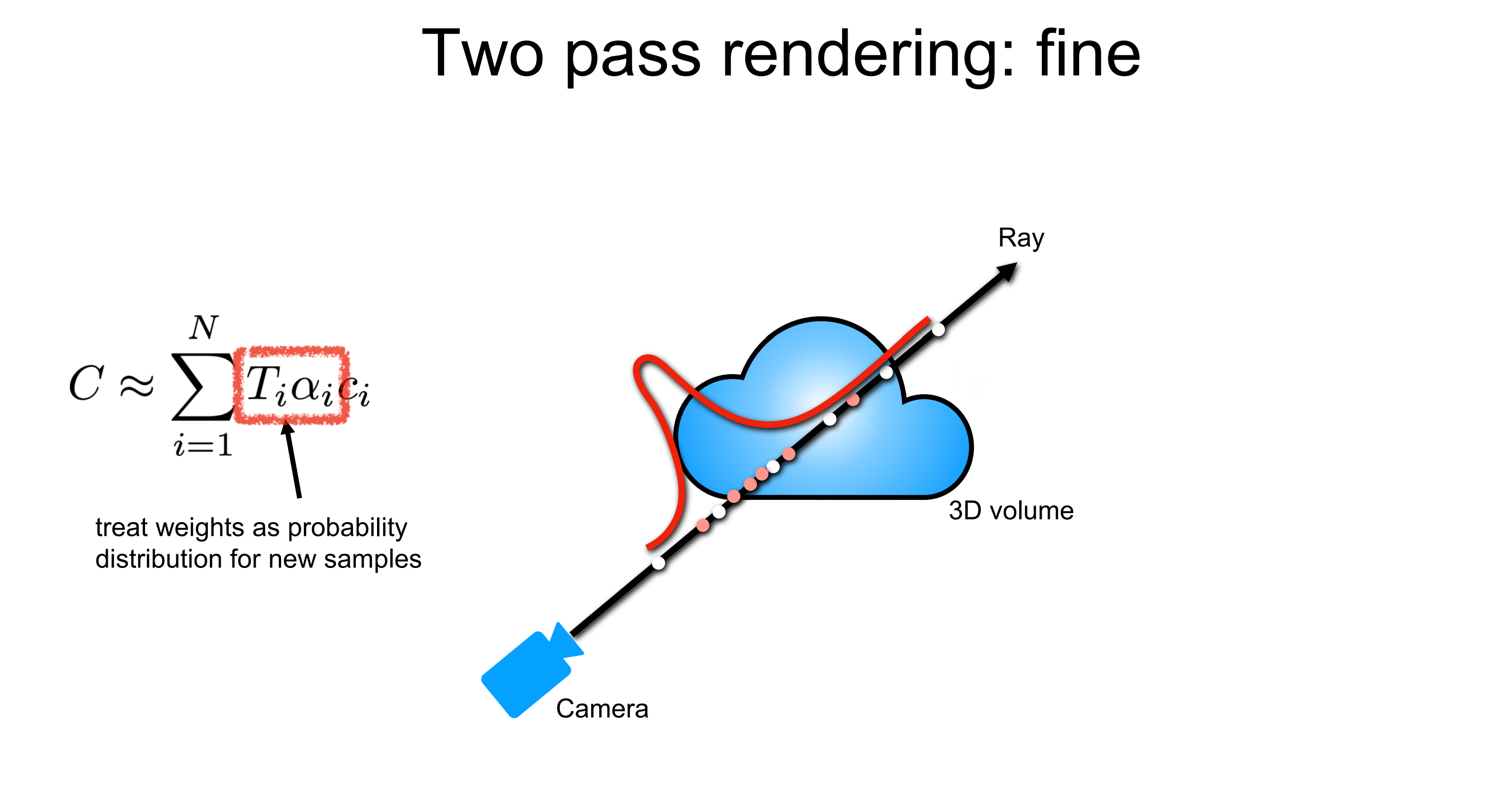
그래서 결과적으로는 Coarse Radiance를 만들어내는 NeRF에도 loss를 걸어줘야 하고 Fine Radiance를 만들어내는 NeRF에도 loss를 걸어줘야 하니 loss function이 다음과 같이 정의되는 것입니다.
- Coarse Radiance : Ray r에 대해서 Nc개의 샘플을 stratified sampling 하여 Cc(r) 계산
- Fine Radiance : Cc(r) 계산에 쓰인 가중치를 고려한 importance sampling을 통해 Nc+Nf개의 샘플로 Cf(r) 계산

이렇게 되면 한 scene에 대해서 모든 view를 한 번 학습한다고 할 때 coarse sampling시 point의 개수 Cc를 64, fine sampling의 개수 Cf를 128로 설정하면 하나의 ray 즉 하나의 픽셀에 대해서 2 pass시에는 (64) + (64+128)로 총 256개의 points를 sampling 하는 것입니다. 이때 NeRF에서는 batch의 단위를 ray들의 set으로 정의합니다. 따라서 4096개의 ray를 한 배치로 정의하게 되면 총 256* 4096개의 points가 한 배치마다 학습되는 것입니다. ( 이렇게 NeRF는 한 scene에 대해서 이러한 Iteration을 100-300k로 학습된다. 논문에서는 nvidia v100으로 한 scene을 하는데 1-2일 학습시간이 소요된다고 한다. 이렇듯 NeRF는 하나의 Scene에 대해서 학습 시에 엄청 많은 시간과 computing cost가 소모되는 것이다. )
한 가지 주의할 점은 결국 NeRF에서 이렇게 coarse network와 fine network를 모두 학습시키지만, 즉 각각의 네트워크에서 나온 radiance에 모두 loss를 걸어주지만, inference와 같은 final rendering에서는 결국 fine network만 사용한다는 점입니다. 하지만, coarse network도 결국 좋은 weight distribution(density를 고려한)을 이해하기 위해서 학습될 필요가 있기에 다음과 같이 loss를 각각 걸어서 결합해주고, coarse network는 fine network의 샘플들을 할당하기 위해서 사용됩니다.
4. Results
그래서 Naive 한 NeRF에 이렇게 Optimization을 해주게 되면 다른 방법들에 비해서 월등히 좋은 결과가 나오게 됩니다. 본 논문에서는 이러한 NeRF가 다른 방법들에 비해서 좋다는 것을 정량적 지표와 정성적 지표를 통해 보여주고 있습니다. 두 가지 지표에서 말하고자 하는 바는 동일합니다. 대부분의 지표, 데이터셋 들에서 NeRF는 기존의 방법론들보다 아득히 뛰어난 새로운 방법이라는 것입니다.
quantitative performance
기존의 DeepVoxel Dataset, 저자들의 합성 데이터셋, 현실의 데이터셋 등에 대해서 이미지의 퀄리티를 판단할 수 있는 지표를 이용해 확인해본 결과 대부분 NeRF가 압도적인 결과를 보여줬다는 것입니다.
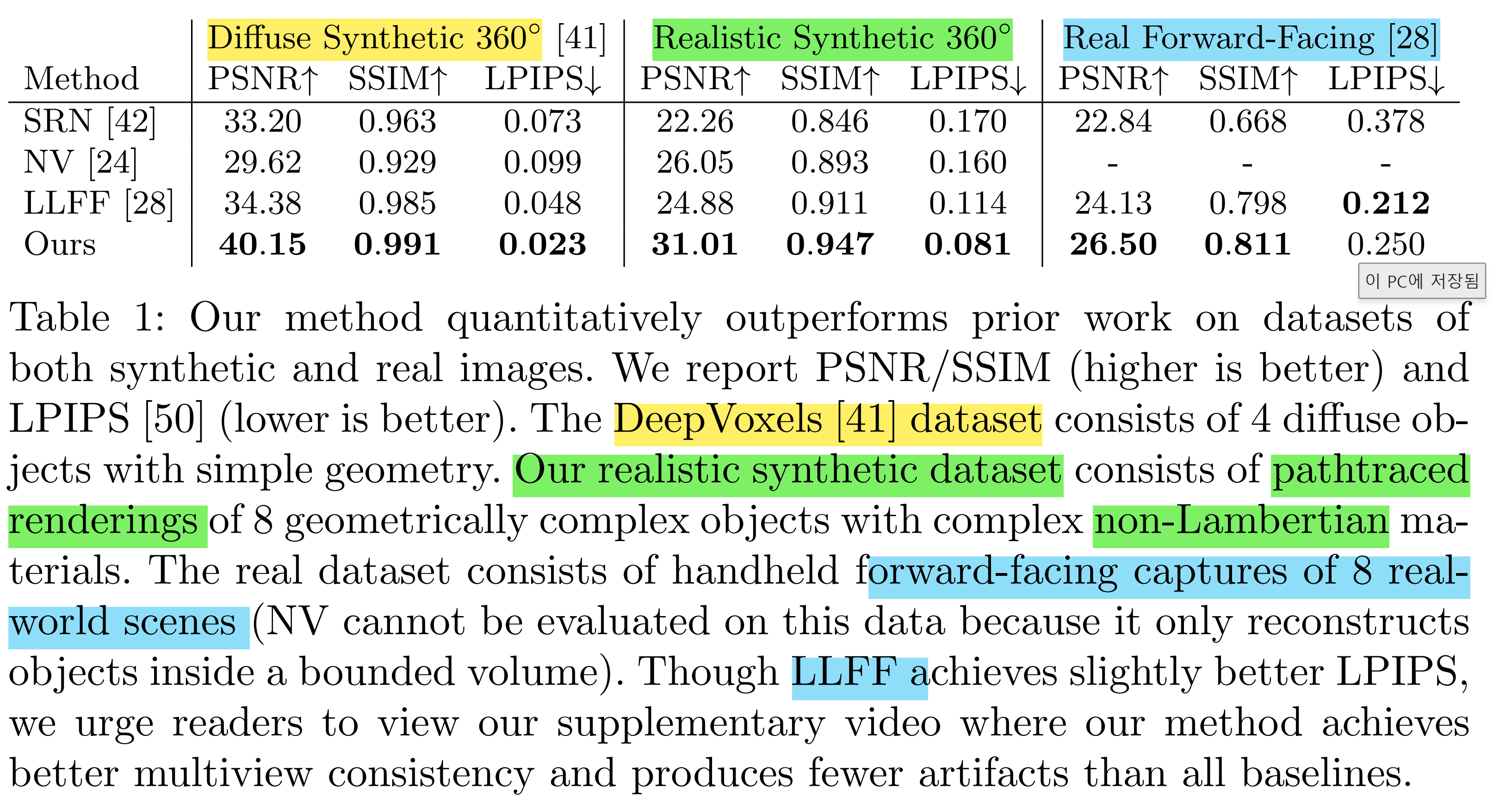
qualititive performance
다른 방법론들과 정량적으로 비교해보더라도 저자들이 제시한 NeRF가 아주 sharp 하고 물리적 현상까지 고려해서 훨씬 깔끔한 결과를 만들어내고 있음을 확인할 수 있습니다.


5. Conclusion
그래서 결과적으로 Novel View Synthesis에서 5d coordinates(x, y, z, θ, φ)를 입력으로 받아 color와 density를 출력하는 MLP Network를 학습해 Sparase 한 view들만을 가지고 3d scene을 이해해 classical volume rendering을 거쳐 새로운 view를 합성할 수 있도록 하는 view synthesis의 새로운 방식인 NeRF를 제시했습니다. 또한, 이러한 NeRF는 매우 좋은 결과를 만들어냈기에 분야가 확장되어 SLAM, Image Synthesis 등 3d aware 한 정보를 이용할 수 있는 다양한 task, domain들에서 무척 적극적으로 활용하는 연구가 이루어지고 있습니다. 물론 NeRF자체도 초기 모델이기에 개선될 수 있는 부분들을 개선하면서 연구가 쏟아지듯이 많이 되고 있습니다. 이러한 NeRF는 등장 이후부터 지금까지 그리고 앞으로도 Vision 및 Graphics에서 엄청난 영향력을 행사할 것이기에 잘 이해해두는 것이 좋을 것 같습니다.
References
- Novel View Synthesis ( University of Illinois - Derek Hoiem ) *Many slides adapted from Lana Lazebnik, Steve Seitz, Yasu Furukawa, Noah Snavely
- Kookmin University Visual Computing Lab - Junho Kim Lecture
- https://jrc-park.tistory.com/m/286
- https://arxiv.org/pdf/2006.09661.pdf
- https://nuggy875.tistory.com/168
- https://www.notion.so/Implicit-Representation-Using-Neural-Network-c6aac62e0bf044ebbe70abcdb9cc3dd1
- https://nuguziii.github.io/cg/CG-001/
'Paper Review > NeRF' 카테고리의 다른 글
| [Paper Review] Plenoxels: Radiance Fields without Neural Networks ( CVPR' 22 Oral ) (0) | 2023.04.24 |
|---|
