GAN Inversion 이란?
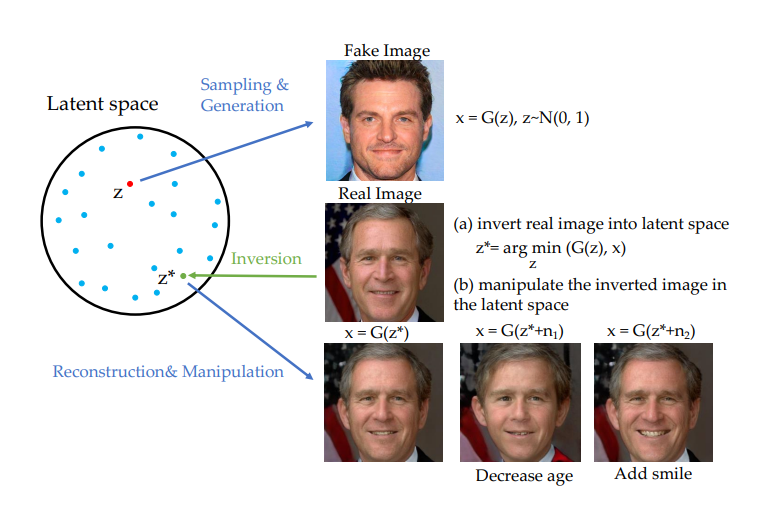
GAN Inversion이란 입력 이미지와 유사한 결과 이미지를 얻을 수 있도록 하는 latent vector를 찾는 과정입니다. 일반적으로 GAN이 학습되면 random latent vector로부터 이미지를 생성해낼 수 있게 됩니다.GAN Inversion은 이의 역과정입니다. 우리가 latent vector를 알기 원하는 이미지를 넣었을 때 GAN의 latent space의 latent vector로 input image를 inverting시키는 것입니다.그렇다면 이러한 이미지의 latent vector를 왜 알고 싶은 것일까요?
Why GAN Inversion?
이러한 GAN Inversion은 StyleGAN이 등장하면서 학습된 StyleGAN을 downstream task들을 위해서 사용하는 것이 핫한 연구 주제가 되며 부각되었습니다. 특히 그 중 하나인 Image Manipulation이 크게 주목받았습니다. ( 즉 점차 GAN을 Application에서 실질적으로 활용하는 측면에서 GAN을 어떻게 사용할지가 고민되며 고안되었습니다. ) StyleGAN의 핵심 아이디어인 latent space의 disentanglement는 latent space에서 특정 attribute의 direction만 찾는다면 사용자가 원하는 대로 이미지를 editing할 수 있다고 생각했기 때문입니다. ( 즉, 사용자가 원하는 semantic 정보를 원하는 방향으로 바꿀 수 있다는 것입니다. )
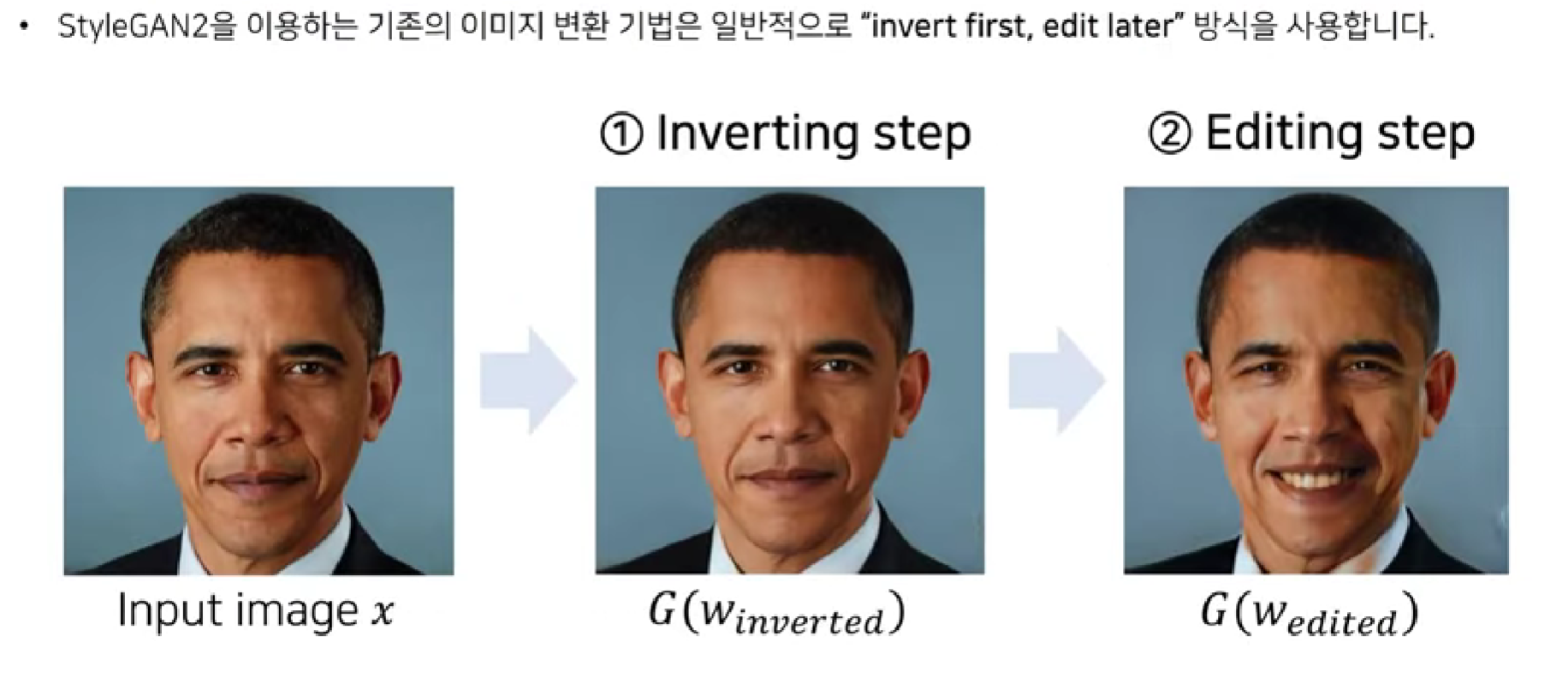
Invert first, Edit later
일반적으로 StyleGAN을 이용하는 image manipulation 방식은 input image를 먼저 원하는 latent space상의 latent vector로 invert해준 뒤에(inverting) 해당 latent vector를 원하는 semantic 변형 방향의 특정 vector를 더해 operation된 latent vector를 만들어내고(editing) 다시 generator에 태워 editing된 이미지를 얻는 방식입니다. 즉, latent vector를 변경함으로써 semantic manipulation을 하는 것으로 특정 이미지를 editing하고자 한다면 해당 이미지를 먼저 latent space로 projection시켜야하고 그 후 target attribute direction으로 modify 시켜줘야 했습니다.
정리하자면 real-world의 이미지가 주어진다면 먼저 해당 이미지의 latnet code를 찾는 inverting step과 이렇게 찾은 latent code를 우리가 원하는 target attribute에 맞게 이동함으로써 edited image를 만들어내는 editing step이 존재하는 것입니다.
따라서 실제로 원하는 이미지를 만들어내거나 이미지를 원하는 방향으로 변화시키는 수요가 존재하는 Practical Domain에서 실제로 GAN이 사용되기 위해서 GAN Inversion의 중요성은 부각되었습니다. 물론 이외에도 StyleGAN 논문에서도 살펴볼 수 있듯이 Fixed StyleGAN을 사용해서 Image Editing을 함으로써 생성 모델의 Quality Evaluation을 하기도 합니다. 따라서 GAN Inversion은 다방면에서 중요한 분야입니다.
Two Methods of GAN Inversion
이러한 GAN Inversion에는 크게 두 가지 방식이 존재합니다. Encoder-free Method 와 Encoder-based Method입니다.

1. Encoder-free Method
전자가 GAN Invesion의 convnetional한 방식으로 다음과 같습니다. Trainable Parameter가 존재하지 않고 latent vector 자체를 optimizatoin해주는 것으로 예를 들어 reconstruction되기를 원하는 이미지 즉, invert되기를 원하는 input image가 있을 때 랜덤한 latent vector로부터 생성된 fake image가 원하는 input image와 같아질 수 있도록 measure를 한 후에 이걸 최적화하기 위해서 latent vector 자체를 계속 optimization하는 방식인 것입니다.( gradient descnet를 통해서) 즉, 수백 수천번의 multiple iterations를 거치면서 점차 랜덤 했던 latent vector가 generator를 통해서 input image를 reconstruct해낼 수 있는 inverted latent vector로 optimization되는 것입니다.
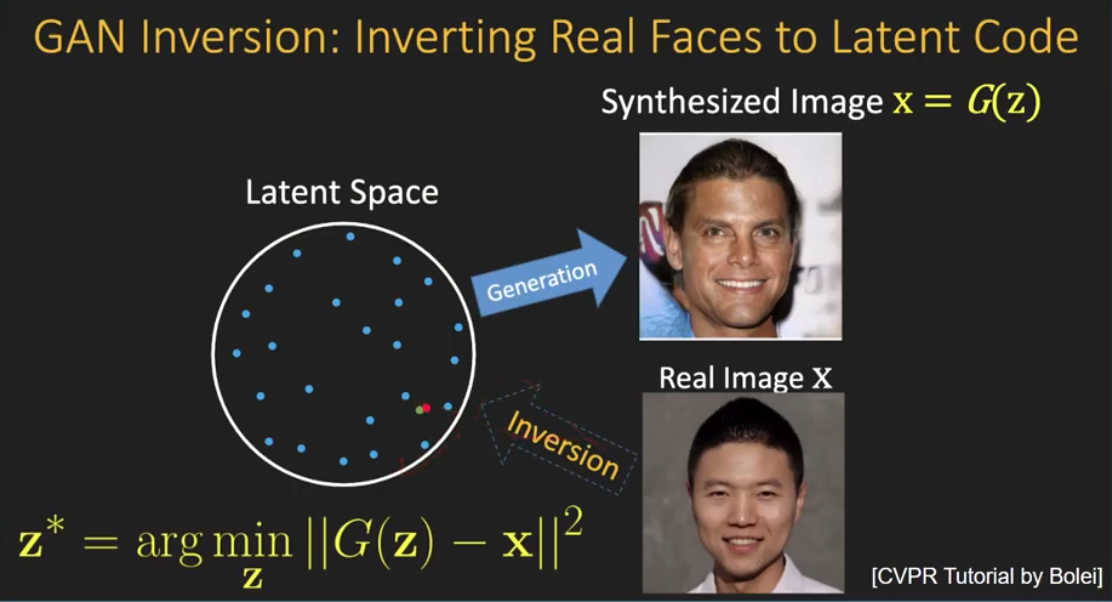
하지만, 이러한 Optimization을 하는 Encoder-free Method는 복잡한 latent structure를 다루기에 적절하지 못합니다. 또한, multi step iteration을 통해서 좋은 latent code를 찾더라도 한 이미지에 대해서 Inversion을 하기 위해서 multi step iteration을 거쳐야 한다는 것은 무척 비효율적이고, reconstruction loss를 바탕으로 latent vector 자체를 업데이트하는 방식은 editibility관점에서도 접근성이 좋지 않습니다. optimization을 통해서 editing을 하려면 optimization과정에 editing이 반영되어야 하는데, training parameter가 없기에 접근 방식들이 제한적이고 올드합니다.
2. Encoder-based Method
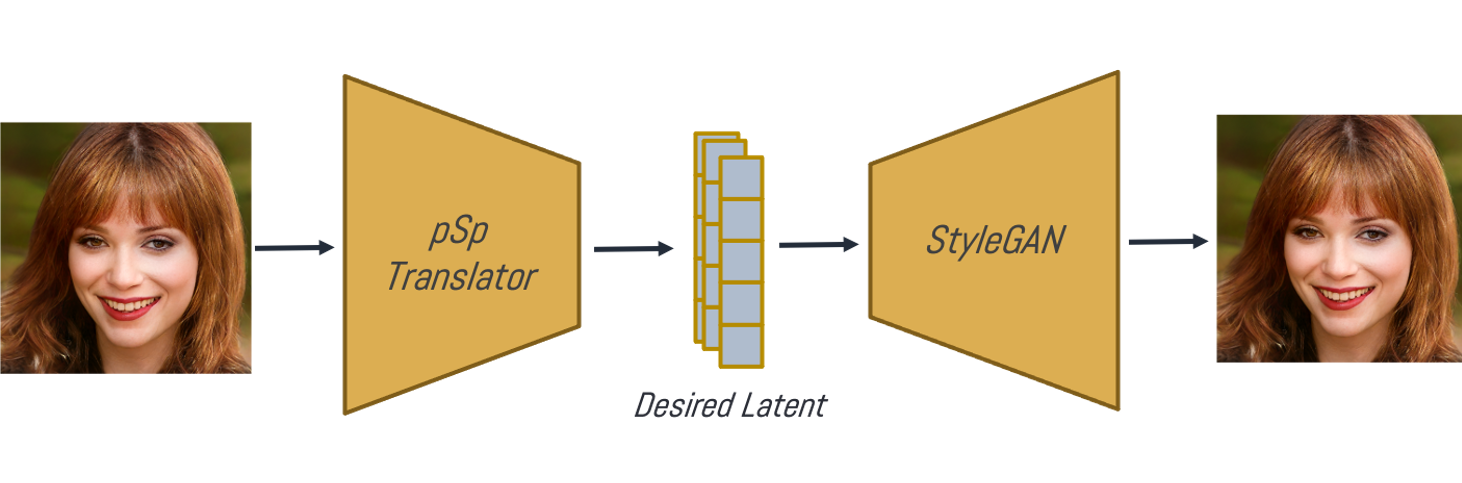
따라서 이러한 encoder free method의 비효율적인 측면과 editing의 관점에서의 부적절함 때문에 최근에는 대부분의 gan inversion연구가 encoder -based method를 통해서 바로 inverted latent vector를 뱉는 encoder network를 학습시키고 있습니다.( 혹은 두 가지 방법을 합치는 Hybird방식도 존재합니다. encoder 네트워크를 opimization을 위한 좋은 inital point를 찾기 위해 사용하고 나서, 추가적으로 latent vector optimization을 진행하는 방식입니다. )
Encoder-based Method는 애초에 목적 자체가 모든 이미지들에 대해서 inversion을 얻을 수 있게 하고자 했기에 아주 효율적이며( 특히 inference ) trainable parameter를 가진 network를 사용하기에 기존의 다른 정보들을 사용하던 conditional network나 sub information을 사용하는 대부분의 방법론의 아이디어를 사용하기도 쉬워 editing 하기에도 훨씬 용이합니다.
Future : Latent Navigation
물론 지금도 GAN Inversion에서 더 나아가 Image Editing등 Application적으로 활용하는 쪽도 많이 연구가 되고 있지만, 우선은 GAN Inversion이 잘 되어야 Application도 효용을 가지기에 Inversion Method자체에도 연구가 많이 됐었습니다. 하지만, Inversion은 궁극적인 목표가 아닙니다. Inversion을 하는 이유는 inverted image를 latent space상에서 manipulation함으로써 특정한 attribute manipulation을 하는 일종의 latent navigation이 큰 목표입니다. 물론 Manipulation 자체로도 하나의 독립적인 연구분야이지만, Manipulation에 있어 Inversion은 빼놓을 수 없는 부분입니다. 따라서 Inversion에서 그치는 것이 아닌 그 뒤의 Application 혹은 Latent Navigation까지 가야하는 것이 궁극적인 목표라는 것을 명확히 인지해야 합니다.
'Concept > Computer Vision' 카테고리의 다른 글
| [Concept] Depth from Defocus (0) | 2023.03.27 |
|---|---|
| [Concept] Lens related Issues (0) | 2023.03.27 |
| [Concept] Image Formation using Lens (0) | 2023.03.27 |


